
Reading Notes on BPF Performance Tools
- Ch 1 Introduction
- Ch 2 Technology Background
- Ch 3 Performance Analysis
- Ch 4 BCC
- Ch 5 bpftrace
- Ch 6 CPUs
- Ch 7 Memory
- Ch 8 File Systems
- Ch 9 Disk I/O
- Ch 13 Applications
- Ch 14 Kernel
- Ch 18 Tips, Tricks and Common Problems
Chapter 3. Performance Analysis
This chapter is a crash course in performance analysis.
3.1 OVERVIEW
3.1.1 Goals
- Latency: How long to accomplish a request or operation, typically measured in milliseconds.
- Rate: An operation or request rate per second.
- Throughput: Typically data movement in bits or bytes per second.
- Utilization: How busy a resource is over time as a percentage.
- Cost: The price/performance ratio.
3.1.2 Activities
| Performance Activity | BPF Performance Tools | |
|---|---|---|
| 1 | Performance characterization of prototype software or hardware | To measure latency histograms under different workloads. |
| 2 | Performance analysis of development code, pre-integration | To solve performance bottlenecks, and find general performance improvements. |
| 3 | Perform no-regression testing of software builds, pre- or post-release | To record code usage and latency from different sources, allowing faster resolution of regressions. |
| 4 | Benchmarking/benchmarketing for software releases | To study performance to find opportunities to improve benchmark numbers. |
| 5 | Proof-of-concept testing in the target environment | To generate latency histograms to ensure that performance meets request latency service level agreements. |
| 6 | Monitoring of running production software | For creating tools that can run 24x7 to expose new metrics that would otherwise be blind spots. |
| 7 | Performance analysis of issues | To solve a given performance issue with tools and custom instrumentation as needed. |
3.2 PERFORMANCE METHODOLOGIES
A methodology is a process you can follow, which provides a starting point, steps, and an ending point.
3.2.1 Workload Characterization
Suggested steps for performing workload characterization:
- Who is causing the load? (PID, process name, UID, IP address, …)
- Why is the load called? (code path, stack trace, flame graph)
- What is the load? (IOPS, throughput, type)
- How is the load changing over time? (per-interval summaries)
3.2.2 Drill-Down Analysis
3.2.3 USE Method
For every resource, check:
- Utilization
- Saturation
- Errors
3.2.4 Checklists
3.3 LINUX 60-SECOND ANALYSIS
uptimedmesg | tailvmstat 1mpstat -P ALL 1pidstat 1iostat -xz 1free -msar -n DEV 1sar -n TCP,ETCP 1top
These commands may enable you to solve some performance issues outright.
-
uptime
A high 15-minute load average coupled with a low 1-minute load average can be a sign that you logged in too late to catch the issue. -
dmesg | tail vmstat 1# vmstat 1 -w procs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu-------- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 325288 90884 1146872 0 0 1 1 5 5 0 0 99 0 0 0 0 0 325288 90884 1146872 0 0 0 0 309 257 0 0 100 0 0 0 0 0 325288 90884 1146872 0 0 0 0 296 264 0 0 100 0 0 0 0 0 325164 90884 1146872 0 0 0 0 277 261 0 0 100 0 0 0 0 0 325164 90884 1146872 0 0 0 0 301 251 0 0 100 0 0 0 0 0 325164 90884 1146872 0 0 0 0 285 260 0 0 100 0 0- r: To interpret: an “r” value greater than the CPU count is saturation.
- si, so: Swap-ins and swap-outs. If these are non-zero, you’re out of memory.
mpstat -P ALL 1$ mpstat -P ALL 1 [...] 03:16:41 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 03:16:42 AM all 14.27 0.00 0.75 0.44 0.00 0.00 0.06 0.00 0.00 84.48 03:16:42 AM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 [...]CPU 0 has hit 100% user time, evidence of a single thread bottleneck. Also look out for high %iowait time, which can be then explored with disk I/O tools, and high %sys time, which can then be explored with syscall and kernel tracing, and CPU profiling.
-
pidstat 1
pidstat provides rolling output by default, so that variation over time can be seen. iostat -xz 1$ iostat -xz 1 Linux 4.13.0-19-generic (...) 08/04/2018 _x86_64_ (16 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.19 0.00 0.31 0.02 0.00 99.48 22.90 0.00 0.82 0.63 0.06 75.59 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util nvme0n1 0.00 1167.00 0.00 1220.00 0.00 151293.00 248.02 2.10 1.72 0.00 1.72 0.21 26.00 nvme1n1 0.00 1164.00 0.00 1219.00 0.00 151384.00 248.37 0.90 0.74 0.00 0.74 0.19 23.60 md0 0.00 0.00 0.00 4770.00 0.00 303113.00 127.09 0.00 0.00 0.00 0.00 0.00 0.00 [...]- r/s, w/s, rkB/s, wkB/s: These are the delivered reads, writes, read Kbytes, and write Kbytes per second to the device. Use these for workload characterization. A performance problem may simply be due to an excessive load applied.
- await: The average time for the I/O in milliseconds. This is the time that the application suffers, as it includes both time queued and time being serviced. Larger than expected average times can be an indicator of device saturation, or device problems.
- avgqu-sz: The average number of requests issued to the device. Values greater than one can be evidence of saturation (although devices, especially virtual devices which front multiple back-end disks, can typically operate on requests in parallel.)
- %util: Device utilization. This is really a busy percent, showing the time each second that the device was doing work. It does not show utilization in a capacity planning sense, as devices can operate on requests in parallel. Values greater than 60% typically lead to poor performance (which should be seen in the await column), although it depends on the device. Values close to 100% usually indicate saturation.
-
free -m
Check that the available value is not near zero: it shows how much real memory is available in the system, including in the buffer and page. sar -n DEV 1sar -n DEV 1 Linux 5.7.8+ (arm-64) 08/29/2020 _aarch64_ (8 CPU) 01:46:42 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 01:46:43 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 01:46:43 PM eth0 2.00 2.00 0.15 0.24 0.00 0.00 0.00 0.00-ncan be used to look at network device metrics. Check interface throughput rxkB/s and txkB/s to see if any limit may have been reached.sar -n TCP,ETCP 1# sar -n TCP,ETCP 1 Linux 5.7.8+ (arm-64) 08/29/2020 _aarch64_ (8 CPU) 01:51:53 PM active/s passive/s iseg/s oseg/s 01:51:54 PM 0.00 0.00 1.00 1.00 01:51:53 PM atmptf/s estres/s retrans/s isegerr/s orsts/s 01:51:54 PM 0.00 0.00 0.00 0.00 0.00 01:51:54 PM active/s passive/s iseg/s oseg/s 01:51:55 PM 0.00 0.00 3.00 3.00 01:51:54 PM atmptf/s estres/s retrans/s isegerr/s orsts/s 01:51:55 PM 0.00 0.00 0.00 0.00 0.00Now we’re using sar to look at TCP metrics and TCP errors. Columns to check:
- active/s: Number of locally-initiated TCP connections per second (e.g., via connect()).
- passive/s: Number of remotely-initiated TCP connections per second (e.g., via accept()).
- retrans/s: Number of TCP retransmits per second.
Active and passive connection counts are useful for workload characterization. Retransmits are a sign of a network or remote host issue.
top
3.4 BCC TOOL CHECKLIST
- execsnoop
- opensnoop
- ext4slower (or btrfs*, xfs*, zfs*)
- biolatency
- biosnoop
- cachestat
- tcpconnect
- tcpaccept
- tcpretrans
- runqlat
runqlat times how long threads were waiting for their turn on CPU. - profile
profile is a CPU profiler, a tool to understand which code paths are consuming CPU resources.
Chapter 6. CPUs
Learning objectives:
- Understand CPU modes, the behavior of the CPU scheduler, and CPU caches.
- Understand areas for CPU scheduler, usage, and hardware analysis with BPF.
- Learn a strategy for successful analysis of CPU performance.
- Solve issues of short-lived processes consuming CPU resources.
- Discover and quantify issues of run queue latency.
- Determine CPU usage through profiled stack traces, and function counts.
- Determine reasons why threads block and leave the CPU.
- Understand system CPU time by tracing syscalls.
- Investigate CPU consumption by soft and hard interrupts.
- Use bpftrace one-liners to explore CPU usage in custom ways.
6.1 BACKGROUND
6.1.1 CPU Modes
- system mode
- user mode
6.1.2 CPU Scheduler
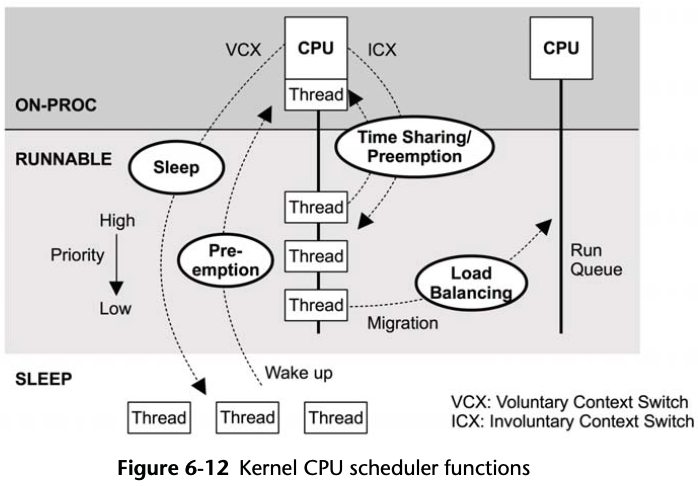
Figure 6-1 CPU scheduler
CFS scheduler uses a red-black tree of future task execution.
Threads leave the CPU in one of two ways:
- voluntary, if they block on I/O, a lock, or a sleep;
- involuntary, if they have exceeded their scheduled allocation of CPU time and are descheduled so that other threads can run, or if they are pre-empted by a higher-priority thread. When a CPU switches from running one thread to another, it switches address spaces and other metadata: this is called a context switch.
Thread migrations: If a thread is in the runnable state and sitting in a run queue while another CPU is idle, the scheduler may migrate the thread to the idle CPU’s run queue so that it can execute sooner.
As a performance optimization, the scheduler implements CPU affinity: the scheduler only migrates threads after they have exceeded a wait time threshold, so that if their wait was short they avoid migration and instead run again on the same CPU where the hardware caches should still be warm.
6.1.3 CPU Caches
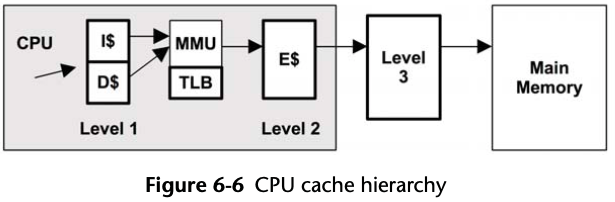
Figure 6-2 hardware caches.
L1 cache, which is split into separate instruction (I$) and data (D$) caches, and is also small (Kbytes) and fast (nanoseconds).
The caches end with the last level cache (LLC), which is large (Mbytes) and much slower.
The memory management unit (MMU) responsible for translating virtual to physical addresses also has its own cache, the translation lookaside buffer (TLB).
6.1.4 BPF Capabilities
- What new processes are created? What is their lifespan?
- Why is system time high? Is it syscalls? What are they doing?
- How long do threads spend on-CPU for each wakeup?
- How long do threads spend waiting on the run queues?
- What is the maximum length of the run queues?
- Are the run queues balanced across the CPUs?
- Why are threads voluntarily leaving the CPU? For how long?
- What soft and hard IRQs are consuming CPUs?
- How often are CPUs idle when work is available on other run queues?
- What is the LLC hit ratio by application request?
Event Sources
| Event Type | Event Source |
|---|---|
| Kernel functions | kpreobes,kretprobes |
| User-level functions | uprobes, uretprobes |
| System calls | syscall tracepoints |
| Soft interrupts | irq:softirq* tracepoints |
| Hard interrupts | irq:irq_handler* tracepoints |
| Workqueue events | workqueue tracepoints |
| Timed sampling | PMC- or time-based sampling |
| CPU power events | power tracepoints |
| CPU cycles | PMCs |
Overhead
In the worst case, scheduler tracing can add over 10% overhead to a system.
- Infrequent events, such as process execution and thread migrations (with at most thousands of events per second) can be instrumented with negligible overhead.
- Profiling (timed sampling) also limits overhead to the fixed rate of samples, reducing overhead to negligible proportions.
6.1.5 Strategy
- Ensure that a CPU workload is running before you spend time with analysis tools. Check system CPU utilization (eg, using mpstat) and that all the CPUs are still online (and some haven’t been offlined for whatever reason).
- Confirm that the workload is CPU-bound.
- Look for high CPU utilization system-wide or on a single CPU (e.g., using mpstat).
- Look for high run queue latency (e.g., using BCC runqlat). Software limits such as cgroups can artificially limit the CPU available to processes, so an application may be CPU-bound on a mostly idle system. This counter-intuitive scenario can be revealed by studying run queue latency.
- Quantify CPU usage as percent utilization system wide, then broken down by process,
CPU mode, and CPU ID. This can be done using traditional tools (e.g., mpstat,
top). Look for high utilization by a single process, mode, or CPU.
- For high system time, frequency count system calls by process and call type, and also examine arguments to look for inefficiencies (eg, using bpftrace one-liners, perf, BCC sysstat).
- Use a profiler to sample stack traces, which can be visualized as a CPU flame graph. Many CPU issues can be found by browsing such flame graphs.
- For CPU consumers identified by profilers, consider writing custom tools to show
more context. Profilers show the functions that are running, but not the arguments
and objects they are operating on, which may be needed to understand CPU usage.
Examples:
- Kernel mode: if a file system is CPU busy doing stat() on files, what are their file names? (e.g., using BCC statsnoop, or in general using tracepoints or kprobes from BPF tools).
- User-mode: If an application is busy processing requests, what are the requests? (e.g., if an application-specific tool is unavailable, one could be developed using USDT or uprobes and BPF tools).
- Measure time in hardware interrupts, since this time may not be visible in timer-based profilers (e.g., BCC hardirqs).
- Browse and execute the BPF tools listed in the BPF tools section of this book.
- Measure CPU instructions-per-cycle (IPC) using PMCs to explain at a high level how much the CPUs are stalled (e.g., using perf). This can be explored with more PMCs, which may identify low cache hit ratios (e.g., BCC llcstat), temperature stalls, etc.
6.2 TRADITIONAL TOOLS
Table of traditional tools
| Tool | Type | Description |
|---|---|---|
| uptime | Kernel Statistics | Show load averages and system uptime |
| top | Kernel Statistics | Show CPU tie by process, and CPU mode times system wide |
| mpstat | Kernel Statistics | Show CPU mode time by CPU |
| perf | Kernel Statistics, Hardware Statistics, Event Tracing | A multi-tool with many subcommands. Profile (timed sampling) of stack traces and event statistics and tracing of PMCs, tracepoints, USDT, kprobes, and uprobes. |
| Ftrace | Kernel Statistics, Event Tracing | Kernel function count statistics, and event tracing of kprobes and uprobes |
6.2.1 Kernel Statistics
Load Averages
$ uptime
00:34:10 up 6:29, 1 user, load average: 20.29, 18.90, 18.70
The load averages are not simple averages (means), but are exponentially damped moving sums, and reflect time beyond one, five, and 15 minutes. The metrics that these summarize show demand on the system: tasks in the CPU runnable state, as well as tasks in the uninterruptible wait state. If you assume that the load averages are showing CPU load, you can divide them by the CPU count to see whether the system is running at CPU saturation – this would be indicated by a ratio of over 1.0. However, a number of problems with load averages, including their inclusion of uninterruptible tasks (those blocked in disk I/O and locks) cast doubt on this interpretation, so they are only really useful for looking at trends over time. You must use other tools, such as the BPF-based offcputime, to see if the load is CPU- or uninterruptible-time based.
top
Tools such as pidstat(1) can be used to print rolling output of process CPU usage
for this purpose, as well as monitoring systems that record process usage.
tiptop which sources PMCs, atop which uses process events to display short-lived processes, and the biotop and tcptop tools I developed which use BPF.
mpstat
This can be used to identify issues of balance, where some CPUs have high utilization
while others are idle.
This can occur for a number of reasons, such as:
- applications misconfigured with a thread pool size too small to utilize all CPUs
- software limits that limit a process or container to a subset of CPUs
- software bugs
6.2.2 Hardware Statistics
perf
The perf stat command counts events specified with -e arguments. If no arguments
are supplied, it defaults to a basic set of PMCs, or an extended set if -d is used.
Depending on your processor type and perf version, you may find a detailed list of PMCs shown using perf list.
There are hundreds of PMCs available, together with model specific registers (MSRs) you can determine how CPU internal components are performing:
- the current clock rate of the CPUs
- their temperatures and energy consumption
- the throughput on CPU interconnects and memory busses
- and more.
6.2.3 Hardware Sampling
6.2.4 Timed Sampling
These provide a coarse, cheap-to-collect view of which software is consuming CPU resources: the sample rate can be tuned to be negligible. There are also different types of profilers, some operating in user-mode only and some in kernel-mode. Kernel-mode profilers are usually preferred, as they can capture both kernel- and user-level stacks, providing a more complete picture.
perf
# echo 0 > /proc/sys/kernel/kptr_restrict
# perf record -F 99 -a -g -- sleep 10
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.883 MB perf.data (7192 samples) ]
# perf report -n --stdio
99 Hertz was chosen instead of 100 to avoid lockstep sampling with other software routines, which would otherwise skew the samples.
Roughly 100 was chosen instead of say 10 or 10,000 as a balance between detail and overhead: too low, and you don’t get enough samples to see the full picture of execution, including large and small code paths; too high, and the overhead of samples skews performance and results.
CPU Flame Graphs
git clone https://github.com/brendangregg/FlameGraph
# cd FlameGraph
# perf record -F 49 -ag -- sleep 30
# perf script --header | ./stackcollapse-perf.pl | ./flamegraph.pl > flame1.svg
At Netflix we have developed a newer flame graph implementation using d3, and an additional tool that can read perf script output: FlameScope, which visualizes profiles as subsecond offset heatmap, from which time ranges can be selected to see the flame graph.
Internals
6.2.5 Event Statistics and Tracing
perf
perf can instrument tracepoints, kprobes, uprobes, and (as of recently) USDT as
well.
As an example, consider an issue where system-wide CPU utilization is high, but
there is no visible process responsible in top. The issue could be short-lived
processes.
To test this hypothesis, count the sched_process_exec tracepoint system-wide using
perf script to show the rate of exec() family syscalls:
# perf stat -e sched:sched_process_exec -I 1000
# time counts unit events
1.000258841 169 sched:sched_process_exec
2.000550707 168 sched:sched_process_exec
3.000676643 167 sched:sched_process_exec
4.000880905 167 sched:sched_process_exec
[...]
# an example of idle system
# perf stat -e sched:sched_process_exec -I 1000
# time counts unit events
1.001371124 0 sched:sched_process_exec
2.002853416 0 sched:sched_process_exec
3.004027371 0 sched:sched_process_exec
4.005679831 1 sched:sched_process_exec
# perf record -e sched:sched_process_exec -a
# perf script
perf has a special subcommand for CPU scheduler analysis called perf sched.
It uses a dump-and-post-process approach for analyzing scheduler behavior, and
provides various reports that can show the CPU runtime per wakeup, the average
and maximum scheduler latency (delay), and ASCII visualizations to show thread
execution per-CPU and migrations.
# perf sched record -- sleep 1
# perf sched timehist
Samples do not have callchains.
time cpu task name wait time sch delay run time
[tid/pid] (msec) (msec) (msec)
--------------- ------ ------------------------------ --------- --------- ---------
888653.810953 [0000] perf_5.7[274586] 0.000 0.000 0.000
888653.811013 [0000] migration/0[11] 0.000 0.011 0.059
888653.811146 [0001] perf_5.7[274586] 0.000 0.000 0.000
888653.811180 [0001] migration/1[15] 0.000 0.007 0.033
However, the dump-and-post-process style is costly.
Where possible, use BPF instead as it can do in-kernel summaries that answer similar questions, and emit the results (for example, the runqlat and runqlen tools).
Ftrace
perf-tools collection mostly uses Ftrace for instrumentation.
Function calls consume CPU, and their names often provide clues as to the workload performed.
6.3 BPF TOOLS
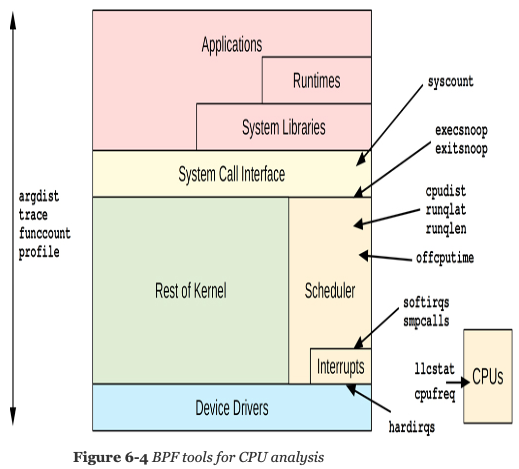
Table of CPU-related tools
| Tool | Source | Target | Overhead | Description |
|---|---|---|---|---|
| execsnoop | bcc/bt | Sched | negligible | List new process execution |
| exitsnoop | bcc | Sched | negligible | Show process lifespan and exit reason |
| runqlat | bcc/bt | Sched | noticeable | Summarize CPU run queue latency |
| runqlen | bcc/bt | Sched | negligible | Summarize CPU run queue length |
| runqslower | bcc | Sched | noticeable* | Print run queue waits slower than a threshold |
| cpudist | bcc | Sched | significant | Summarize on-CPU time |
| cpufreq | book | CPUs | negligible | Sample CPU frequency by process |
| profile | bcc | CPUs | negligible | Sample CPU stack traces |
| offcputime | bcc/book | Sched | significant | Summarize off-CPU stack traces and times |
| syscount | bcc/bt | Syscalls | noticeable* | Count system calls by type and process |
| argdist | bcc | Syscalls | Can be used for syscall analysis | |
| trace | bcc | Syscalls | Can be used for syscall analysis | |
| funccount | bcc | Software | significant* | Count function calls |
| softirqs | bcc | Interrupts | high* | Summarize soft interrupt time |
| hardirqs | bcc | Interrupts | Summarize hard interrupt time | |
| smpcalls | book | Kernel | Time SMP remote CPU calls | |
| llcstat | bcc | PMCs | Summarize LLC hit ratio by process |
6.3.1 execsnoop
It can find issues of short-lived processes that consume CPU resources and can also be used to debug software execution, including application start scripts.
execsnoop(8) has been used to debug many production issues: perturbations from background jobs, slow or failing application startup, slow or failing container startup, etc.
Some applications create new processes without calling exec(2), for example, when creating a pool of worker processes using fork(2) or clone(2) alone.
This situation should be uncommon: applications should be creating pools of worker threads, not processes.
Since the rate of process execution is expected to be relatively low (<1000/sec), the overhead of this tool is expected to be negligible.
execsnoop.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("%-10s %-5s %s\n", "TIME(ms)", "PID", "ARGS");
}
tracepoint:syscalls:sys_enter_execve
{
printf("%-10u %-5d ", elapsed / 1000000, pid);
join(args->argv);
}
6.3.2 exitsnoop
exitsnoop(8) traces when processes exit, showing their age and exit reason. The age is the time from process creation to termination, and includes time both on and off CPU.
# exitsnoop-bpfcc
PCOMM PID PPID TID AGE(s) EXIT_CODE
agetty 275283 1 275283 10.02 code 1
agetty 275284 1 275284 10.03 code 1
agetty 275285 1 275285 10.03 code 1
agetty 275286 1 275286 10.03 code 1
agetty 275287 1 275287 10.03 code 1
This works by instrumenting the sched:sched_process_exit tracepoint and its
arguments, and also uses bpf_get_current_task() so that the start time can be
read from the task struct (an unstable interface detail).
Since this tracepoint should fire infrequently, the overhead of this tool should be negligible.
6.3.3 runqlat
runqlat is a tool to measure CPU scheduler latency. This is useful for identifying and quantifying issues of CPU saturation, where there is more demand for CPU resources than they can service. The metric measured by runqlat is the time each thread (task) spends waiting for its turn on CPU.
# runqlat-bpfcc 10 1
Tracing run queue latency... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 66 |*** |
8 -> 15 : 31 |* |
16 -> 31 : 704 |****************************************|
32 -> 63 : 507 |**************************** |
64 -> 127 : 66 |*** |
128 -> 255 : 8 | |
256 -> 511 : 7 | |
512 -> 1023 : 2 | |
1024 -> 2047 : 0 | |
2048 -> 4095 : 2 | |
4096 -> 8191 : 1 | |
runqlat(8) works by instrumenting scheduler wakeup and context switch events to determine the time from wakeup to running. These events can be very frequent on busy production systems, exceeding one million events per second. Even though BPF is optimized, at these rates even adding one microsecond per event can cause noticeable overhead .
Misconfigured Build
Here is a different example for comparison, this time a 36-CPU build server doing
a software build, where the number of parallel jobs has been set to 72 by mistake,
causing the CPUs to be overloaded:
# runqlat 10 1
Tracing run queue latency... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 1906 |*** |
2 -> 3 : 22087 |****************************************|
4 -> 7 : 21245 |************************************** |
8 -> 15 : 7333 |************* |
16 -> 31 : 4902 |******** |
32 -> 63 : 6002 |********** |
64 -> 127 : 7370 |************* |
128 -> 255 : 13001 |*********************** |
256 -> 511 : 4823 |******** |
512 -> 1023 : 1519 |** |
1024 -> 2047 : 3682 |****** |
2048 -> 4095 : 3170 |***** |
4096 -> 8191 : 5759 |********** |
8192 -> 16383 : 14549 |************************** |
16384 -> 32767 : 5589 |********** |
32768 -> 65535 : 372 | |
65536 -> 131071 : 10 | |
The distribution is now bi-modal, with a second mode centered in the eight to 16 millisecond bucket. This shows significant waiting by threads.
This particular issue is straightforward to identify from other tools and metrics. For example, sar can show CPU utilization (-u) and run queue metrics (-q):
# sar -uq 1
Linux 4.18.0-virtual (...) 01/21/2019 _x86_64_ (36 CPU)
11:06:25 PM CPU %user %nice %system %iowait %steal %idle
11:06:26 PM all 88.06 0.00 11.94 0.00 0.00 0.00
11:06:25 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
11:06:26 PM 72 1030 65.90 41.52 34.75 0
[...]
This sar(1) output shows 0% CPU idle and an average run queue size of 72 (which includes both running and runnable) – more than the 36 CPUs available.
runqlat.bt
#!/usr/bin/env bpftrace
#include <linux/sched.h>
BEGIN
{
printf("Tracing CPU scheduler... Hit Ctrl-C to end.\n");
}
tracepoint:sched:sched_wakeup,
tracepoint:sched:sched_wakeup_new
{
@qtime[args->pid] = nsecs;
}
tracepoint:sched:sched_switch
{
if (args->prev_state == TASK_RUNNING) {
@qtime[args->prev_pid] = nsecs;
}
$ns = @qtime[args->next_pid];
if ($ns) {
@usecs = hist((nsecs - $ns) / 1000);
}
delete(@qtime[args->next_pid]);
}
END
{
clear(@qtime);
}
6.3.4 runqlen
runqlen is a tool to sample the length of the CPU run queues, counting how many tasks are waiting their turn.
I’d describe run queue length as a secondary performance metric, and run queue latency as primary.
This timed sampling has negligible overhead compared to runqlat’s scheduler tracing. For 24x7 monitoring, it may be preferable to use runqlen first to identify issues (since it is cheaper to run), and then use runqlat ad hoc to quantify the latency.
This per-CPU output (with -C option) is useful for checking scheduler balance.
# runqlen-bpfcc -TC 1
Sampling run queue length... Hit Ctrl-C to end.
02:55:30
cpu = 2
runqlen : count distribution
0 : 99 |****************************************|
cpu = 4
runqlen : count distribution
0 : 99 |****************************************|
cpu = 3
runqlen : count distribution
0 : 99 |****************************************|
cpu = 1
runqlen : count distribution
0 : 99 |****************************************|
cpu = 5
runqlen : count distribution
0 : 99 |****************************************|
cpu = 6
runqlen : count distribution
0 : 99 |****************************************|
cpu = 7
runqlen : count distribution
0 : 99 |****************************************|
cpu = 0
runqlen : count distribution
0 : 99 |****************************************|
Run queue occupancy (-O) is a separate metric that shows the percentage of time
that there were threads waiting.
# runqlen-bpfcc -TOC 1
Sampling run queue length... Hit Ctrl-C to end.
02:58:00
runqocc, CPU 0 0.00%
runqocc, CPU 1 0.00%
runqocc, CPU 2 0.00%
runqocc, CPU 3 0.00%
runqocc, CPU 4 0.00%
runqocc, CPU 5 0.00%
runqocc, CPU 6 0.00%
runqocc, CPU 7 0.00%
runqlen.bt
#!/usr/bin/env bpftrace
#include <linux/sched.h>
// Until BTF is available, we'll need to declare some of this struct manually,
// since it isn't available to be #included. This will need maintenance to match
// your kernel version. It is from kernel/sched/sched.h:
struct cfs_rq_partial {
struct load_weight load;
unsigned long runnable_weight;
unsigned int nr_running;
unsigned int h_nr_running;
};
BEGIN
{
printf("Sampling run queue length at 99 Hertz... Hit Ctrl-C to end.\n");
}
profile:hz:99
{
$task = (struct task_struct *)curtask;
$my_q = (struct cfs_rq_partial *)$task->se.cfs_rq;
$len = $my_q->nr_running;
$len = $len > 0 ? $len - 1 : 0; // subtract currently running task
@runqlen = lhist($len, 0, 100, 1);
}
This bpftrace version can break down by CPU, by adding a cpu key to @runqlen.
6.3.5 runqslower
runqslower lists instances of run queue latency exceeding a threshold (default is 10ms).
# runqslower-bpfcc
Tracing run queue latency higher than 10000 us
TIME COMM PID LAT(us)
03:05:41 b'kworker/6:1' 70686 12046
03:05:41 b'systemd' 1 12603
[...]
This currently works by using kprobes for the kernel functions ttwu_do_wakeup(), wake_up_new_task(), and finish_task_switch().
A future version should switch to scheduler tracepoints, using code similar to the earlier bpftrace version of runqlat.
The overhead is similar to that of runqlat; it can cause noticeable overhead on busy systems due to the cost of the kprobes, even while runqslower is not printing any output.
6.3.6 cpudist
cpudist show distribution of on-CPU time for each thread wakeup. This can be used to help characterize CPU workloads, providing details for later tuning and design decisions.
# cpudist -m
Tracing on-CPU time... Hit Ctrl-C to end.
^C
msecs : count distribution
0 -> 1 : 521 |****************************************|
2 -> 3 : 60 |*** |
4 -> 7 : 272 |******************** |
8 -> 15 : 308 |*********************** |
16 -> 31 : 66 |***** |
32 -> 63 : 14 |* |
The mode of on-CPU durations from 4 to 15 milliseconds is likely threads exhausting their scheduler time quanta and then encountering an involuntary context switch.
This works by tracing scheduler context switch events, which can be very frequent on busy production workloads (>1M events/sec). As with runqlat, the overhead of this tool could be significant.
6.3.7 cpufreq
cpufreq samples the CPU frequency and shows it as a system-wide histogram, with per-process name histograms.
The performance overhead should be low to negligible.
cpufreq.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Sampling CPU freq system-wide & by process. Ctrl-C to end.\n");
}
tracepoint:power:cpu_frequency
{
@curfreq[cpu] = args->state;
}
profile:hz:100
/@curfreq[cpu]/
{
@system_mhz = lhist(@curfreq[cpu] / 1000, 0, 5000, 200);
if (pid) {
@process_mhz[comm] = lhist(@curfreq[cpu] / 1000, 0, 5000, 200);
}
}
END
{
clear(@curfreq);
}
The frequency changes are traced using the power:cpu_frequency tracepoint, and saved in a @curfreq BPF map by CPU, for later lookup while sampling. The histograms track frequencies from 0 to 5000 MHz in steps of 200 MHz; these parameters can be adjusted in the tool if needed.
6.3.8 profile
profile samples stack traces at a timed interval, and emits a frequency count of stack traces. This is the most useful tool for understanding CPU consumption as it summarizes almost all code paths that are consuming CPU resources (see hardirq for more CPU consumers).
It can also be used with relatively negligible overhead, as the event rate is fixed to the sample rate, which can be tuned.
By default, it samples both user and kernel stack traces at 49 Hertz across all CPUs. This can be customized using options.
CPU Flame Graphs
Flame graphs are a visualization of stack traces, and can help you quickly understand
profile output.
# profile -af 30 > out.stacks01
$ git clone https://github.com/brendangregg/FlameGraph
$ cd FlameGraph
$ ./flamegraph.pl --color=java < ../out.stacks01 > out.svg
The hottest code paths are the widest towers.
profile is different from other CPU profilers, it calculates frequency count in kernel space for efficiency. Other kernel-based profilers, such as perf, emit each sampled stack trace to user space, where it is post-processed into a summary. This can be CPU expensive and, depending on the invocation, it can also involve file system and disk I/O to record the samples. profile avoids those expenses.
The core functionality can be implemented as a bpftrace one-liner:
bpftrace -e 'profile:hz:49 /pid/ { @samples[ustack, kstack, comm] = count(); }'
6.3.9 offcputime
offcputime is used to summarize time spent by threads blocked and off-CPU, showing stack traces to explain why. For CPU analysis, this explains why threads are not running on CPU. It’s a counterpart to profile: between them, they show the entire time spent by threads on the system, both on-CPU with profile and off-CPU with offcputime.
offcputime has been used to find various production issues, including finding unexpected time blocked in lock acquisition and the stack traces responsible.
offcputime works by instrumenting context switches and recording the time from when a thread leaves the CPU to when it returns, along with the stack trace. The times and stack traces are frequency-counted in kernel context for efficiency. Context switch events can nonetheless be very frequent, and the overhead of this tool can become significant (say, >10%) for busy production workloads.
Off-CPU Time Flame Graphs
# offcputime -fKu 5 > out.offcputime01.txt
$ flamegraph.pl --hash --bgcolors=blue -- title="Off-CPU Time Flame Graph" \
< out.offcputime01.txt > out.offcputime01.svg
By filtering to only record one PID or stack type can help reduce overhead.
offcputime.bt
#!/usr/bin/bpftrace
#include <linux/sched.h>
BEGIN
{
printf("Tracing nanosecond time in off-CPU stacks. Hit Ctrl-C to end.\n");
}
kprobe:finish_task_switch
{
// record previous thread sleep time
$prev = (struct task_struct *)arg0;
if ($1 == 0 || $prev->tgid == $1) {
@start[$prev->pid] = nsecs;
}
// get the current thread start time
$last = @start[tid];
if ($last != 0) {
@[kstack, ustack, comm] = sum(nsecs - $last);
delete(@start[tid]);
}
}
END
{
clear(@start);
}
6.3.10 syscount
syscount is a tool to count system calls system-wide.
It can be a starting point for investigating cases of high system CPU time.
sudo apt install auditd -y
# syscount-bpfcc -i 1
Tracing syscalls, printing top 10... Ctrl+C to quit.
[14:21:04]
SYSCALL COUNT
pselect6 57
read 53
bpf 13
rt_sigprocmask 8
write 5
ioctl 3
gettid 3
epoll_pwait 2
getpid 2
timerfd_settime 1
The -P option can be used to count by process ID instead:
# syscount-bpfcc -Pi 1
Tracing syscalls, printing top 10... Ctrl+C to quit.
[14:22:06]
PID COMM COUNT
1 systemd 349
741 systemd-journal 109
2544 agent-proxy 102
809 systemd-logind 32
774 dbus-daemon 29
802 rsyslogd 21
283137 syscount-bpfcc 19
282033 sshd 18
282989 auditd 6
782 NetworkManager 2
The overhead of this tool may become noticeable for very high syscall rates.
Similar bpftrace one-liner:
# bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
Attaching 286 probes...
^C
[...]
@[tracepoint:syscalls:sys_enter_recvmsg]: 615
@[tracepoint:syscalls:sys_enter_read]: 629
@[tracepoint:syscalls:sys_enter_faccessat]: 787
@[tracepoint:syscalls:sys_enter_close]: 836
@[tracepoint:syscalls:sys_enter_gettid]: 906
@[tracepoint:syscalls:sys_enter_ioctl]: 1327
@[tracepoint:syscalls:sys_enter_epoll_pwait]: 2179
This currently involves a delay during program startup and shutdown to instrument all these tracepoints. It’s preferable to use the single raw_syscalls:sys_enter tracepoint, as BCC does.
6.3.11 argdist & trace
If a syscall was found to be called frequently, we can use these tools to examine it in more detail.
For the tracepoint, we will need to find the argument names, which the BCC tool tplist prints out with the -v option:
# tplist -v syscalls:sys_enter_read
syscalls:sys_enter_read
int __syscall_nr;
unsigned int fd;
char * buf;
size_t count;
# argdist -H 't:syscalls:sys_enter_read():int:args->count'
# bpftrace -e 't:syscalls:sys_enter_read { @ = hist(args->count); }'
# argdist -H 't:syscalls:sys_exit_read():int:args->ret'
# bpftrace -e 't:syscalls:sys_exit_read { @ = hist(args->ret); }'
Examples:
# argdist-bpfcc -H 't:syscalls:sys_enter_read():int:args->count'
[14:51:01]
args->count : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 0 | |
128 -> 255 : 0 | |
256 -> 511 : 0 | |
512 -> 1023 : 0 | |
1024 -> 2047 : 0 | |
2048 -> 4095 : 0 | |
4096 -> 8191 : 0 | |
8192 -> 16383 : 50 |****************************************|
16384 -> 32767 : 1 | |
# bpftrace -e 't:syscalls:sys_enter_read { @ = hist(args->count); }'
Attaching 1 probe...
^C
@:
[8, 16) 1 | |
[16, 32) 0 | |
[32, 64) 0 | |
[64, 128) 0 | |
[128, 256) 0 | |
[256, 512) 0 | |
[512, 1K) 0 | |
[1K, 2K) 0 | |
[2K, 4K) 0 | |
[4K, 8K) 0 | |
[8K, 16K) 279 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16K, 32K) 3 | |
# bpftrace -e 't:syscalls:sys_exit_read { @ = hist(args->ret); }'
Attaching 1 probe...
^C
@:
(..., 0) 3 | |
[0] 38 |@@ |
[1] 700 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[2, 4) 4 | |
[4, 8) 6 | |
[8, 16) 17 |@ |
[16, 32) 6 | |
[32, 64) 18 |@ |
[64, 128) 2 | |
[128, 256) 4 | |
[256, 512) 5 | |
[512, 1K) 12 | |
[1K, 2K) 1 | |
[2K, 4K) 2 | |
bpftrace has a separate bucket for negative values (“(…, 0)”), which are error codes returned by read to indicate an error. We can craft a bpftrace one-liner to print these as a frequency count or a linear histogram, so that their individual numbers can be seen:
# bpftrace -e 't:syscalls:sys_exit_read /args->ret < 0/ { @ = lhist(- args->ret, 0, 100, 1); }'
6.3.12 funccount
funccount is a tool that can frequency-count functions and other events. It can be used to provide more context for software CPU usage, by showing which functions are called and how frequently. profile may show that a function is hot on-CPU, but it can’t explain why: whether the function is slow, or whether it was simply called millions of times per second.
# funccount-bpfcc 'vfs_*'
Tracing 67 functions for "b'vfs_*'"... Hit Ctrl-C to end.
^C
FUNC COUNT
b'vfs_setxattr' 1
b'vfs_symlink' 1
b'vfs_removexattr' 1
b'vfs_unlink' 2
b'vfs_statfs' 2
b'vfs_rename' 2
b'vfs_readlink' 3
b'vfs_rmdir' 4
b'vfs_mkdir' 4
b'vfs_write' 34
b'vfs_lock_file' 68
b'vfs_statx' 84
b'vfs_statx_fd' 87
b'vfs_getattr' 165
b'vfs_getattr_nosec' 165
b'vfs_open' 178
b'vfs_read' 851
Detaching...
# funccount-bpfcc -Ti 5 'vfs_*'
The overhead of this tool is relative to the rate of the functions. Some functions, such as malloc() and get_page_from_freelist(), tend to occur frequently, so tracing them can slow down the target application significantly, in excess of 10%.
# bpftrace -e 'k:vfs_* { @[probe] = count(); }'
# bpftrace -e 'k:vfs_* { @[probe] = count(); } interval:s:1 { print(@); clear(@); }'
6.3.13 softirqs
softirqs is a tool that shows the time spent servicing soft IRQs (soft interrupts).
softirqs can show time per soft IRQ, rather than event count as shown in mpstat
or /proc/softirqs.
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
HI: 12 0 0 0 0 0 0 0
TIMER: 1735349 2682998 1224456 885852 1325406 1300100 844205 796172
NET_TX: 9 32932 8 34075 2 1 1 2
NET_RX: 387770 30291 53536 69207 23892 32315 18903 8850
BLOCK: 103720 17802 14277 8427 33687 18968 17084 7898
IRQ_POLL: 0 0 0 0 0 0 0 0
TASKLET: 986086 401 601 505 129 116 148 88
SCHED: 1371691 2456003 917788 552230 487432 842298 443486 409531
HRTIMER: 0 0 0 0 0 0 0 0
RCU: 976423 786287 703830 621370 660607 806616 608495 556455
It works by using the irq:softirq_enter and irq:softirq_exit tracepoints.
The overhead of this tool is relative to the event rate.
# softirqs-bpfcc 10 1
Tracing soft irq event time... Hit Ctrl-C to end.
SOFTIRQ TOTAL_usecs
net_tx 36
block 222
net_rx 1144
rcu 3468
sched 5401
timer 6496
tasklet 24426
hi 45192
The -d option can be used to explore the distribution, and identify if there are latency outliers while servicing these interrupts.
# softirqs-bpfcc 10 1 -d
Tracing soft irq event time... Hit Ctrl-C to end.
softirq = net_tx
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 1 |****************************************|
32 -> 63 : 1 |****************************************|
softirq = timer
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 8 |*** |
8 -> 15 : 50 |************************ |
16 -> 31 : 82 |****************************************|
32 -> 63 : 65 |******************************* |
64 -> 127 : 1 | |
softirq = hi
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 291 |*********** |
16 -> 31 : 0 | |
32 -> 63 : 1052 |****************************************|
softirq = rcu
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 9 |******** |
8 -> 15 : 42 |****************************************|
16 -> 31 : 39 |************************************* |
32 -> 63 : 8 |******* |
64 -> 127 : 3 |** |
128 -> 255 : 2 |* |
softirq = sched
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 1 | |
4 -> 7 : 13 |***** |
8 -> 15 : 31 |************* |
16 -> 31 : 89 |****************************************|
32 -> 63 : 43 |******************* |
64 -> 127 : 3 |* |
softirq = net_rx
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 1 |************* |
32 -> 63 : 3 |****************************************|
64 -> 127 : 2 |************************** |
128 -> 255 : 2 |************************** |
softirq = block
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 1 |********** |
32 -> 63 : 4 |****************************************|
softirq = tasklet
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 2 | |
16 -> 31 : 121 |************ |
32 -> 63 : 383 |****************************************|
64 -> 127 : 5 | |
6.3.14 hardirqs
hardirqs is a BCC tool that shows time spent servicing hard IRQs (hard interrupts).
# hardirqs 10 1
This currently works by using dynamic tracing of the handle_irq_event_percpu() kernel function, although a future version should switch to the irq:irq_handler_entry and irq:irq_handler_exit tracepoints.
6.3.15 Other Tools
- cpuwalk from bpftrace samples which processes CPUs were running on, printing the result as a linear histogram. This provides a histogram view of CPU balance.
- cpuunclaimed from BCC is an experimental tool that samples CPU run queue lengths and determines how often there are idle CPUs, yet threads in a runnable state on a different run queue. This sometimes happens due to CPU affinity, but if it happens often it may be a sign of a scheduler mis-configuration or bug.
- loads from bpftrace is an example of fetching the load averages from a BPF tool. As discussed earlier, these numbers are misleading.
- vltrace is a tool in development by Intel that will be a BPF-powered version of strace, and can be used for further characterization of syscalls that are consuming CPU time.
6.4 BPF ONE-LINERS
New processes with arguments:
execsnoop
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
Show who is executing what:
trace 't:syscalls:sys_enter_execve "-> %s", args->filename'
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'
Syscall count by program:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
Syscall count by process:
syscount -P
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
Syscall count by syscall name:
syscount
Syscall count by syscall probe name:
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
Sample running process name at 99 Hertz:
bpftrace -e 'profile:hz:99 { @[comm] = count(); }'
Sample user-level stacks at 49 Hertz, for PID 189:
profile -F 49 -U -p 189
bpftrace -e 'profile:hz:49 /pid == 189/ { @[ustack] = count(); }'
Sample all stack traces and process names:
profile
bpftrace -e 'profile:hz:49 { @[ustack, kstack, comm] = count(); }'
Sample running CPU at 99 Hertz and show as a linear histogram:
bpftrace -e 'profile:hz:99 { @cpu = lhist(cpu, 0, 256, 1); }'
Count kernel functions beginning with ‘vfs_’:
funccount 'vfs_*'
bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'
Count SMP calls by name and kernel stack:
bpftrace -e 'kprobe:smp_call* { @[probe, kstack(5)] = count(); }'
6.5 OPTIONAL EXERCISES
- Use execsnoop to show the new processes for the “man ls” command.
- Run execsnoop with -t and output to a log file for ten minutes on a production or local system; what new processes did you find?
- Create an overloaded CPU. This creates two CPU-bound threads that are bound
to CPU 0:
taskset -c 0 sh -c 'while :; do :; done' & taskset -c 0 sh -c 'while :; do :; done' &Now use
uptime(load averages),mpstat(-P ALL),runqlen, andrunqlatto characterize the workload on CPU 0. - Develop a tool/one-liner to sample kernel stacks on CPU 0 only.
- Use profile to capture kernel CPU stacks to determine where CPU time is spent
by the following workload:
dd if=/dev/nvme0n1p3 bs=8k iflag=direct | dd of=/dev/null bs=1Modify the infile (if=) device to be a local disk. You can either profile system-wide, or filter for each of those dd processes.
- Generate a CPU flame graph of the (5) output.
- Use offcputime to capture kernel CPU stacks to determine where blocked time is spent for the (5) workload.
- Generate an off-CPU time flame graph for the (7) output.
- execsnoop only sees new processes that call exec (execve), although some may fork or clone and not exec (e.g., the creation of worker processes). Write a new tool called procsnoop to show all new processes with as many details as possible. You could trace fork and clone, or use the sched tracepoints, or something else.
- Develop a bpftrace version of softirqs that prints the softirq name.
- Implement cpudist in bpftrace.
- With cpudist (either version), show separate histograms for voluntary and involuntary context switches.
- (Advanced, unsolved) Develop a tool to show a histogram of time spent by tasks in CPU affinity wait: runnable while other CPUs are idle, but not migrated due to cache warmth (see kernel.sched_migration_cost_ns, task_hot() (which may be inlined and not tracable), and can_migrate_task()).
Chapter 7. Memory
Learning objectives:
- Understand memory allocation and paging behavior.
- Learn a strategy for successful analysis of memory behavior using tracers.
- Use traditional tools to understand memory capacity usage.
- Use BPF tools to identify code paths causing heap and RSS growth.
- Characterize page faults by filename and stack trace.
- Analyze the behavior of the VM scanner.
- Determine the performance impact of memory reclaim.
- Identify which processes are waiting for swap-ins.
- Use bpftrace one-liners to explore memory usage in custom ways.
7.1 BACKGROUND
7.1.1 Memory Allocators
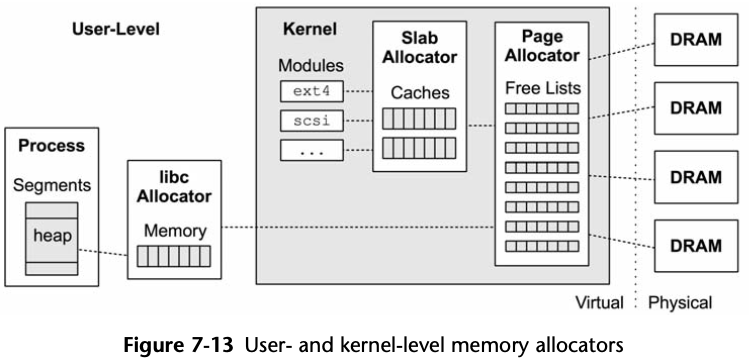 Figure 7-1 Memory Allocators
Figure 7-1 Memory Allocators
For processes using libc for memory allocation, memory is stored on a dynamic segment of the process’ virtual address space called the heap.
libc needs to extend the size of the heap only when there is no available memory.
For efficiency, memory mappings are created in groups of memory called pages.
The kernel can service physical memory page requests from its own free lists, which it maintains for each DRAM group and CPU for efficiency. The kernel’s own software also consumes memory from these free lists as well, usually via a kernel allocator such as the slab allocator.
7.1.2 Memory Pages and Swapping
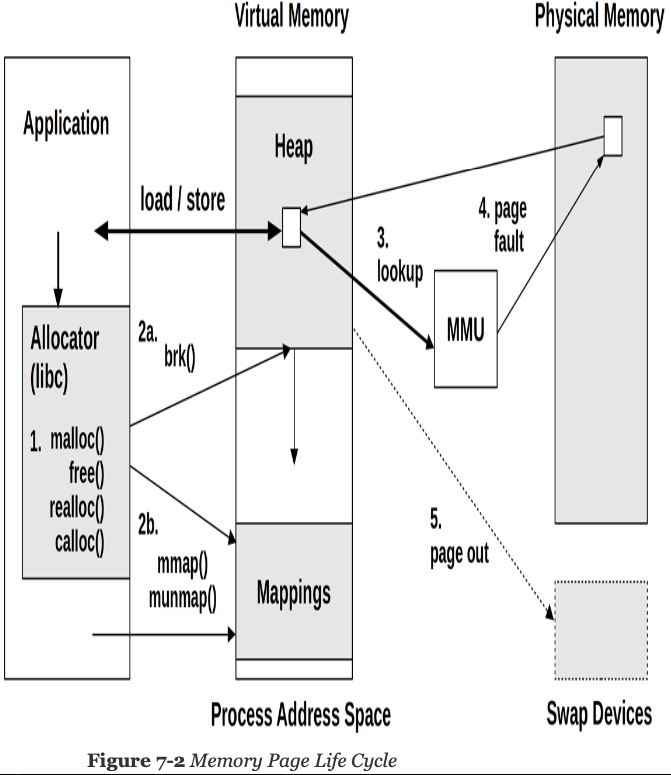
The amount of physical memory in use by the process is called its resident set size (RSS).
kswapd will free one of three types of memory:
a) File system pages that were read from disk and not modified (termed “backed by
disk”). These pages are application-executable text, data, and file system metadata.
b) File system pages that have been modified.
c) Pages of application memory. These are called anonymous memory, because they have no file origin. If swap devices are in use, these can be freed by first storing them on a swap device. This writing of pages to a swap device is termed swapping.
User-level allocations can occur millions of times per second for a busy application. Load and store instructions and MMU lookups are even more frequent, and can occur billions of times per second.
7.1.3 Page-Out Daemon(kswapd)
It is woken up when free memory crosses a low threshold, and goes back to sleep when it crosses a high threshold, as shown below.
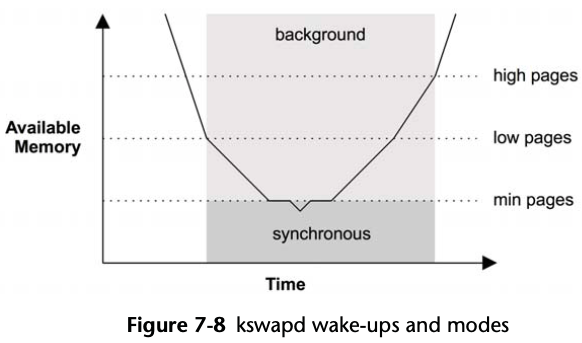 Figure 7-3 kswapd wake-ups and modes
Figure 7-3 kswapd wake-ups and modes
Direct reclaim is a foreground mode of freeing memory to satisfy allocations. In this mode, allocations block (stall) and synchronously wait for pages to be freed.
Direct reclaim can call kernel module shrinker functions: these free up memory that may have been kept in caches, including the kernel slab caches.
7.1.4 Swap Devices
Swap devices provide a degraded mode of operation for a system running out of memory: processes can continue to allocate, but less frequently-used pages are now moved to and from their swap devices, which usually causes applications to run much more slowly.
Some production systems run without swap.
7.1.5 OOM Killer
The heuristic looks for the largest victim that will free many pages, and which isn’t a critical task such as kernel threads or init (PID 1). Linux provides ways to tune the behavior of the OOM killer system-wide and per-process.
7.1.6 Page Compaction
7.1.7 File System Caching and Buffering
Linux can be tuned to prefer freeing from the file system cache, or freeing memory via swapping (vm.swappiness).
7.1.8 BPF Capabilities
BPF tracing tools can provide additional insight for memory activity, answering:
- Why does the process physical memory (RSS) keep growing?
- What code paths are causing page faults? For which files?
- What processes are blocked waiting on swap-ins?
- What memory mappings are being created system-wide?
- What is the system state at the time of an OOM kill?
- What application code paths are allocating memory?
- What types of objects are allocated by applications?
- Are there memory allocations that are not freed after a while? (potential leaks)?
Event Sources
| Event Type | Event Source |
|---|---|
| User memory allocations | uprobe on allocator functions, libc USDT probes |
| Kernel memory allcations | kprobes on allocator functions, kmem tracepoints |
| Heap expansions | brk syscall tracepoint |
| Share memory functions | syscall tracepoints |
| Page faults | kprobes, software events, exception tracepoints |
| Page migrations | migration tracepoints |
| Page compaction | compaction tracepoints |
| VM scanner | vmscan tracepoints |
| Memory access cycles | PMCs |
Overhead
Memory allocation events can occur millions of times per second, calling them
millions of times per second can add up to significant overhead, slowing the target
software by over 10%, and in some cases by ten times (10x),
depending on the rate of events traced and the BPF program used.
Many questions about memory usage can be answered, or approximated, by tracing the infrequent events: page faults, page outs, brk() calls, and mmap() calls. The overhead of tracing these can be negligible.
One reason to trace the malloc() calls is to show the code paths that led to malloc(). These code paths can be revealed using a different technique: timed sampling of CPU stacks, as covered in the previous chapter. Searching for “malloc” in a CPU flame graph is a coarse but cheap way to identify the code paths calling this function frequently.
The performance of uprobes may be greatly improved in the future (10-100x) through dynamic libraries involving user- to user-space jumps, rather than kernel traps.
7.1.9 Strategy
- Check kernel messages to see if the OOM killer has recently killed processes
- Check if the system has swap devices and the amount of swap in use, and if those devices have active I/O (eg, using swap, iostat, vmstat).
- Check the amount of free memory on the system, and system-wide usage by caches (eg, free).
- Check per-process memory usage (eg, using top, ps).
- Check the page fault rate, and examine stack traces on page faults: this can explain RSS growth.
- Check the files that were backing page faults.
- Trace brk() and mmap() calls for a different view of memory usage.
- Browse and execute the BPF tools listed in the BPF tools section of this book.
- Measure hardware cache misses and memory accesses using PMCs (especially with PEBS enabled) to determine functions and instructions causing memory I/O (e.g., using perf).
7.2 TRADITIONAL TOOLS
Table of traditional tools
| Tool | Type | Description |
|---|---|---|
| dmesg | Kernel Log | OOM killer event details |
| swapon | Kernel Statistics | Swap device usage |
| free | Kernel Statistics | System-wide memory usage |
| ps | Kernel Statistics | Process statistics including memory usage |
| pmap | Kernel Statistics | Process memory usage by segment |
| vmstat | Kernel Statistics | Various statistics including memory |
| sar | Kernel Statistics | Can show page fault and page scanner rates |
| perf | Software Events, Hardware Statistics, Hardware Sampling | Memory-related PMC statistics and event sampling |
7.2.1 Kernel Log
OOM
7.2.2 Kernel Statistics
swapon
$ swapon
NAME TYPE SIZE USED PRIO
/dev/sda3 partition 977M 766.2M -2
free
free -w
It includes an “available” column, showing how much memory is available for use, including the file system cache.
ps
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.3 0.5 167232 10412 ? Ss Aug24 33:44 /sbin/init
root 2 0.0 0.0 0 0 ? S Aug24 0:02 [kthreadd]
root 3 0.0 0.0 0 0 ? I< Aug24 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< Aug24 0:00 [rcu_par_gp]
root 8 0.0 0.0 0 0 ? I< Aug24 0:00 [mm_percpu_wq]
root 9 0.0 0.0 0 0 ? S Aug24 0:11 [ksoftirqd/0]
- %MEM: The percentage of the system’s physical memory in use by this process.
- VSZ: Virtual memory size.
- RSS: Resident set size: total physical memory in use by this process.
# ps -eo pid,vsz,rss,name
PID VSZ RSS NAME
1 11984 2560 init
[...]
131 10888 3196 logd
132 5892 3168 servicemanager
133 8468 4916 hwservicemanager
134 5892 3124 vndservicemanager
136 8312 4720 android.hardware.keymaster@3.0-service
138 15156 5540 vold
153 24932 5608 netd
154 1028440 124220 zygote
157 6684 3232 android.hidl.allocator@1.0-service
158 7008 3476 healthd
160 15068 8056 android.hardware.audio@2.0-service
161 6804 3456 android.hardware.bluetooth@1.0-service
162 7584 4112 android.hardware.cas@1.0-service
164 8120 3540 android.hardware.configstore@1.1-service
165 6024 3436 android.hardware.graphics.allocator@2.0-service
166 12324 5476 android.hardware.graphics.composer@2.1-service
167 6716 3252 android.hardware.light@2.0-service.rpi3
169 6876 3364 android.hardware.memtrack@1.0-service
170 5884 3300 android.hardware.power@1.0-service
171 7816 3360 android.hardware.usb@1.0-service
172 7772 5200 android.hardware.wifi@1.0-service
173 43152 18432 audioserver
174 4856 1984 lmkd
176 63772 23744 surfaceflinger
177 8316 3944 thermalserviced
181 4488 2448 sh
182 3908 1032 adbd
187 5056 2384 su
188 24596 11268 cameraserver
189 18092 9756 drmserver
190 9528 4132 incidentd
191 13248 4284 installd
192 11836 6100 keystore
193 9612 5012 mediadrmserver
194 47672 13164 media.extractor
195 17880 9344 media.metrics
197 57552 14464 mediaserver
198 10760 4444 storaged
199 9312 4512 wificond
200 34472 11012 media.codec
201 10160 5220 gatekeeperd
202 8820 3352 perfprofd
203 4652 2344 tombstoned
245 2228 972 mdnsd
263 7424 2456 su
267 5312 1640 su
269 5440 1396 su
270 4488 2444 sh
312 1250296 176172 system_server
444 0 0 [kworker/1:2-mm_percpu_wq]
457 4860 2404 iptables-restore
458 4864 2468 ip6tables-restore
488 0 0 [sdcard]
490 855608 90164 com.android.inputmethod.latin
503 1020396 189740 com.android.systemui
715 875148 94356 com.android.phone
730 933000 103092 com.android.settings
838 849196 79700 com.android.deskclock
868 843104 69808 com.android.se
873 846264 72444 org.lineageos.audiofx
902 843304 71776 com.android.printspooler
920 848376 87940 android.process.media
937 968040 162932 com.android.launcher3
943 841964 69544 com.android.keychain
998 850016 75352 org.lineageos.lineageparts
1027 843752 85916 android.process.acore
1033 847288 77236 com.android.calendar
1077 849404 74056 com.android.contacts
1095 842676 77784 com.android.providers.calendar
1117 843940 70268 com.android.managedprovisioning
1138 0 0 [kworker/u8:2-events_unbound]
1140 839700 68076 com.android.onetimeinitializer
1157 849100 71832 com.android.packageinstaller
1175 847160 76060 com.android.traceur
1196 843736 70612 org.lineageos.lockclock
1214 844616 77912 org.lineageos.updater
[...]
These statistics and more can be found in /proc/PID/status.
pmap
This view can identify large memory consumers by libraries or mapped files.
This extended (-x) output includes a column for “dirty” pages.
# pmap -x `pidof surfaceflinger`
176: /system/bin/surfaceflinger
Address Kbytes PSS Dirty Swap Mode Mapping
0c4e1000 28 28 0 0 r-x-- surfaceflinger
0c4e9000 4 4 4 0 r---- surfaceflinger
0c4ea000 4 4 4 0 rw--- surfaceflinger
e3534000 4592 0 0 0 rw-s- gralloc-buffer (deleted)
e3e40000 1504 0 0 0 rw-s- gralloc-buffer (deleted)
e3fb8000 1504 0 0 0 rw-s- gralloc-buffer (deleted)
e4130000 1504 0 0 0 rw-s- gralloc-buffer (deleted)
e42a8000 1504 750 0 0 rw-s- gralloc-buffer (deleted)
e4a00000 512 136 136 0 rw--- [anon:libc_malloc]
e4aa7000 4 0 0 0 ----- [anon]
e4aa8000 1012 8 8 0 rw--- [anon]
e4ba5000 4 0 0 0 ----- [anon]
e4ba6000 1012 8 8 0 rw--- [anon]
e4ca3000 4 0 0 0 ----- [anon]
e4ca4000 1012 8 8 0 rw--- [anon]
e4f05000 1504 750 0 0 rw-s- gralloc-buffer (deleted)
e507d000 1504 750 0 0 rw-s- gralloc-buffer (deleted)
e51f5000 4592 2112 2112 0 rw-s- gralloc-buffer (deleted)
e5671000 20 5 0 0 r-x-- android.hardware.graphics.allocator@2.0-impl.so
e5676000 4 4 4 0 r---- android.hardware.graphics.allocator@2.0-impl.so
e5677000 4 4 4 0 rw--- android.hardware.graphics.allocator@2.0-impl.so
[...]
-------- ------ ------ ------ ------
total 63772 10506 4900 0
vmstat
sar
The -B option shows page statistics:
# sar -B 1
Linux 4.15.0-1031-aws (...) 01/26/2019 _x86_64_ (48 CPU)
06:10:38 AM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
06:10:39 PM 0.00 0.00 286.00 0.00 16911.00 0.00 0.00 0.00 0.00
06:10:40 PM 0.00 0.00 90.00 0.00 19178.00 0.00 0.00 0.00 0.00
06:10:41 PM 0.00 0.00 187.00 0.00 18949.00 0.00 0.00 0.00 0.00
06:10:42 PM 0.00 0.00 110.00 0.00 24266.00 0.00 0.00 0.00 0.00
[...]
The page fault rate (“fault/s”) is low, less than 300 per second. There also isn’t any page scanning (the “pgscan” columns), indicating that the system is likely not running at memory saturation.
7.2.3 Hardware Statistics and Sampling
7.3 BPF TOOLS
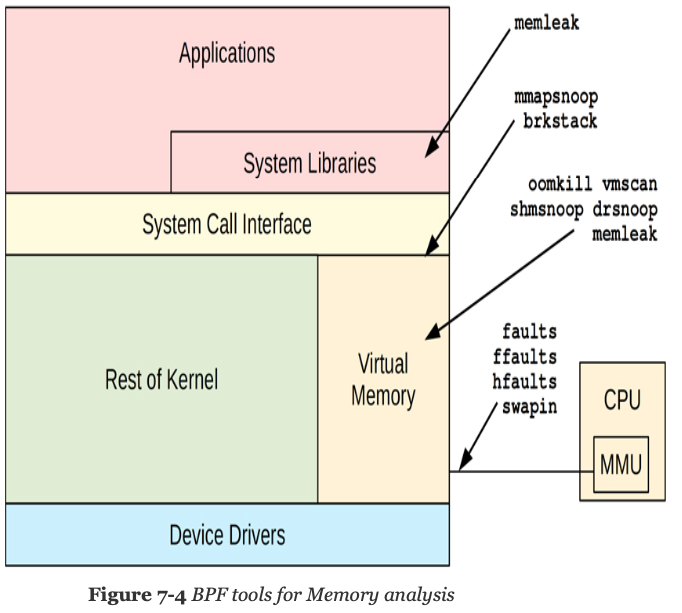
Table of Memory-related tools
| Tools | Source | Target | Overhead | Description |
|---|---|---|---|---|
| oomkill | bcc/bt | OOM | negligible | Show extra info on OOM kill events |
| memleak | bcc | Sched | Show possible memory leak codepaths | |
| mmapsnoop | book | Syscalls | negligible | Trace mmap calls system wide |
| brkstack | book | Syscalls | negligible | Show brk() calls with user stack traces |
| shmsnoop | bcc | Syscalls | negligible | Trace shared memory calls with details |
| faults | book | Faults | Show page faults by user stack trace | |
| ffaults | book | Faults | noticeable* | Show page faults by filename |
| vmscan | book | VM | Measure VM scanner shrink and reclaim times | |
| drsnoop | bcc | VM | negligible | Trace direct reclaim events showing latency |
| swapin | book | VM | Show swap-ins by process | |
| hfaults | book | Faults | Show huge page faults by process |
7.3.1 oomkill
# oomkill
Tracing OOM kills... Ctrl-C to stop.
08:51:34 Triggered by PID 18601 ("perl"), OOM kill of PID 1165 ("java"), 18006224 pages,
loadavg: 10.66 7.17 5.06 2/755 18643
[...]
This tool can be enhanced to print other details as desired when debugging OOM events. There are also oom tracepoints that can reveal more details about how tasks are selected, which are not yet used by this tool.
This tool may also be useful to customize for investigations; for example, by adding other task_struct details at the time of the OOM, or other commands in the system() call.
oomkill.bt
#!/usr/bin/env bpftrace
#include <linux/oom.h>
BEGIN
{
printf("Tracing oom_kill_process()... Hit Ctrl-C to end.\n");
}
kprobe:oom_kill_process
{
$oc = (struct oom_control *)arg0;
time("%H:%M:%S ");
printf("Triggered by PID %d (\"%s\"), ", pid, comm);
printf("OOM kill of PID %d (\"%s\"), %d pages, loadavg: ",
$oc->chosen->pid, $oc->chosen->comm, $oc->totalpages);
cat("/proc/loadavg");
}
7.3.2 memleak
Without a -p PID provided, memleak will trace kernel allocations.
7.3.3 mmapsnoop
This tool works by instrumenting the syscalls:sys_enter_mmap tracepoint.
The overhead of this tool should be negligible as the rate of new mappings should be relatively low.
7.3.4 brkstack
# trace -U t:syscalls:sys_enter_brk
# stackcount -PU t:syscalls:sys_enter_brk
brk growths are infrequent, the overhead of tracing these is negligible, making this an inexpensive tool for finding some clues about memory growth.
The stack trace may reveal a large and unusual allocation that needed more space than was available, or a normal code path that happened to need one byte more than was available. The code path will need to be studied to determine which is the case.
brkstack.bt
#!/usr/bin/bpftrace
tracepoint:syscalls:sys_enter_brk
{
@[ustack, comm] = count();
}
7.3.5 shmsnoop
This can be used for debugging shared memory usage. For example, during startup of a Java application.
This tool works by tracing the shared memory syscalls, which should be infrequent enough that the overhead of the tool is negligible.
7.3.6 faults
These page faults cause RSS growth.
faults.bt
#!/usr/bin/bpftrace
software:page-faults:1
{
@[ustack, comm] = count();
}
7.3.7 ffaults
# ffaults.bt Attaching 1 probe...
[...]
@[cat]: 4576
@[make]: 7054
@[libbfd-2.26.1-system.so]: 8325
@[libtinfo.so.5.9]: 8484
@[libdl-2.23.so]: 9137
@[locale-archive]: 21137
@[cc1]: 23083
@[ld-2.23.so]: 27558
@[bash]: 45236
@[libopcodes-2.26.1-system.so]: 46369
@[libc-2.23.so]: 84814
@[]: 537925
This output shows that the most page faults were to regions without a file name – this would be process heaps – with 537,925 faults occurring during tracing. The libc library encountered 84,814 faults while tracing. This is happening because the software build is creating many short-lived processes, which are faulting in their new address spaces.
ffaults.bt
#!/usr/bin/bpftrace
#include <linux/mm.h>
kprobe:handle_mm_fault
{
$vma = (struct vm_area_struct *)arg0;
$file = $vma->vm_file->f_path.dentry->d_name.name;
@[str($file)] = count();
}
The rate of file faults varies: check using tools such as perf or sar. For high rates, the overhead of this tool may begin to become noticeable.
7.3.8 vmscan
- S-SLABms: Total time in shrink slab, in milliseconds. This is reclaiming memory from various kernel caches.
- D-RECLAIMms: Total time in direct reclaim, in milliseconds. This is foreground reclaim, which blocks memory allocations while memory is written to disk.
- M-RECLAIMms: Total time in memory cgroup reclaim, in milliseconds. If memory cgroups are in use, this shows when one cgroup has exceeded its limit and its own cgroup memory is reclaimed.
- KSWAPD: Number of kswapd wakeups.
- WRITEPAGE: Number of kswapd page writes.
Look out for time in direct reclaims (D-RECLAIMms): this type of reclaim is “bad” but necessary, and will cause performance issues. It can hopefully be eliminated by tuning the other vm sysctl tunables to engage background reclaim sooner.
vmscan.bt
#!/usr/bin/bpftrace
tracepoint:vmscan:mm_shrink_slab_start
{
@start_ss[tid] = nsecs;
}
tracepoint:vmscan:mm_shrink_slab_end
/@start_ss[tid]/
{
$dur_ss = nsecs - @start_ss[tid];
@sum_ss = @sum_ss + $dur_ss;
@shrink_slab_ns = hist($dur_ss);
delete(@start_ss[tid]);
}
tracepoint:vmscan:mm_vmscan_direct_reclaim_begin
{
@start_dr[tid] = nsecs;
}
tracepoint:vmscan:mm_vmscan_direct_reclaim_end
/@start_dr[tid]/
{
$dur_dr = nsecs - @start_dr[tid];
@sum_dr = @sum_dr + $dur_dr;
@direct_reclaim_ns = hist($dur_dr);
delete(@start_dr[tid]);
}
tracepoint:vmscan:mm_vmscan_memcg_reclaim_begin
{
@start_mr[tid] = nsecs;
}
tracepoint:vmscan:mm_vmscan_memcg_reclaim_end
/@start_mr[tid]/
{
$dur_mr = nsecs - @start_mr[tid];
@sum_mr = @sum_mr + $dur_mr;
@memcg_reclaim_ns = hist($dur_mr);
delete(@start_mr[tid]);
}
tracepoint:vmscan:mm_vmscan_wakeup_kswapd
{
@count_wk++;
}
tracepoint:vmscan:mm_vmscan_writepage
{
@count_wp++;
}
BEGIN
{
printf(" %-10s %10s %12s %12s %6s %9s\n", "TIME",
"S-SLABms", "D-RECLAIMms", "M-RECLAIMms", "KSWAPD", "WRITEPAGE");
}
interval:s:1
{
time("%H:%M:%S");
printf(" %10d %12d %12d %6d %9d\n",
@sum_ss / 1000000, @sum_dr / 1000000, @sum_mr / 1000000,
@count_wk, @count_wp);
clear(@sum_ss);
clear(@sum_dr);
clear(@sum_mr);
clear(@count_wk);
clear(@count_wp);
}
7.3.9 drsnoop
# drsnoop -T
TIME(s) COMM PID LAT(ms) PAGES
0.000000000 java 11266 1.72 57
0.004007000 java 11266 3.21 57
0.011856000 java 11266 2.02 43
0.018315000 java 11266 3.09 55
0.024647000 acpid 1209 6.46 73
[...]
The rate of these and their duration can be considered in quantifying the application impact.
These are expected to be low-frequency events (usually happening in bursts), so the overhead should be negligible.
7.3.10 swapin
Swap-ins occur when the application tries to use memory that has been moved to the swap device. This is an important measure of the performance pain suffered by the application due to swapping.
Other swap metrics, like scanning and swap-outs, may not directly affect application performance.
swapin.bt
#!/usr/bin/bpftrace
kprobe:swap_readpage
{
@[comm, pid] = count();
}
interval:s:1
{
time();
print(@);
clear(@);
}
7.3.11 hfaults
hfaults traces huge page faults by their process details, and can be used to
confirm that huge pages are in use.
hfaults.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing Huge Page faults per process... Hit Ctrl-C to end.\n");
}
kprobe:hugetlb_fault
{
@[pid, comm] = count();
}
7.4 BPF ONE-LINERS
Count process heap expansion (brk()) by user-level stack trace:
stackcount -U t:syscalls:sys_enter_brk
bpftrace -e 'tracepoint:syscalls:sys_enter_brk { @[ustack, comm] = count(); }'
Count vmscan operations by tracepoint:
funccount 't:vmscan:*'
bpftrace -e 'tracepoint:vmscan:* { @[probe] = count(); }'
Show hugepages madvise() calls by process:
trace hugepage_madvise
bpftrace -e 'kprobe:hugepage_madvise { printf("%s by PID %d\n", probe, pid); }'
Count page migrations:
funccount t:migrate:mm_migrate_pages
bpftrace -e 'tracepoint:migrate:mm_migrate_pages { @ = count(); }'
Trace compaction events:
trace t:compaction:mm_compaction_begin
bpftrace -e 't:compaction:mm_compaction_begin { time(); }'
7.5 OPTIONAL EXERCISES
- Run vmscan for ten minutes on a production or local server. If any time was spent in direct reclaim (D-RECLAIMms), also run drsnoop to measure this on a per-event basis.
- Modify vmscan to print the header every 20 lines, so that it remains on screen.
- During application startup (either a production or desktop application) use fault to count page fault stack traces. This may involve fixing or finding an application that supports stack traces and symbols.
- Create a page fault flame graph from the output of (3).
- Develop a tool to trace process virtual memory growth via both brk and mmap.
- Develop a tool to print the size of expansions via brk. This may use syscall tracepoints, kprobes, or libc USDT probes as desired.
- Develop a tool to show the time spent in page compaction. You can use the compaction:mm_compaction_begin and compaction:mm_compaction_end tracepoints. Print the time per event, and summarize it as a histogram.
- Develop a tool to show time spent in shrink slab, broken down by slab name (or shrinker function name).
- Use memleak to find long-term survivors on some sample software in a test environment. Also estimate the performance overhead with and without memleak running.
- (Advanced, unsolved) Develop a tool to investigate swap thrashing: show the time spent by pages on the swap device as a histogram. This likely involves measuring the time from swap out to swap in.
Chapter 8. File Systems
Learning objectives:
- Understand file system components: VFS, caches, write-back.
- Understand targets for file system analysis with BPF.
- Learn a strategy for successful analysis of file system performance.
- Characterize file system workloads by file, operation type, and by process.
- Measure latency distributions for file system operations, and identify bi-modal distributions and issues of latency outliers.
- Measure the latency of file system write-back events.
- Analyze page cache and read ahead performance.
- Observe directory and inode cache behavior.
- Use bpftrace one-liners to explore file system usage in custom ways.
8.1 BACKGROUND
8.1.1 I/O Stack
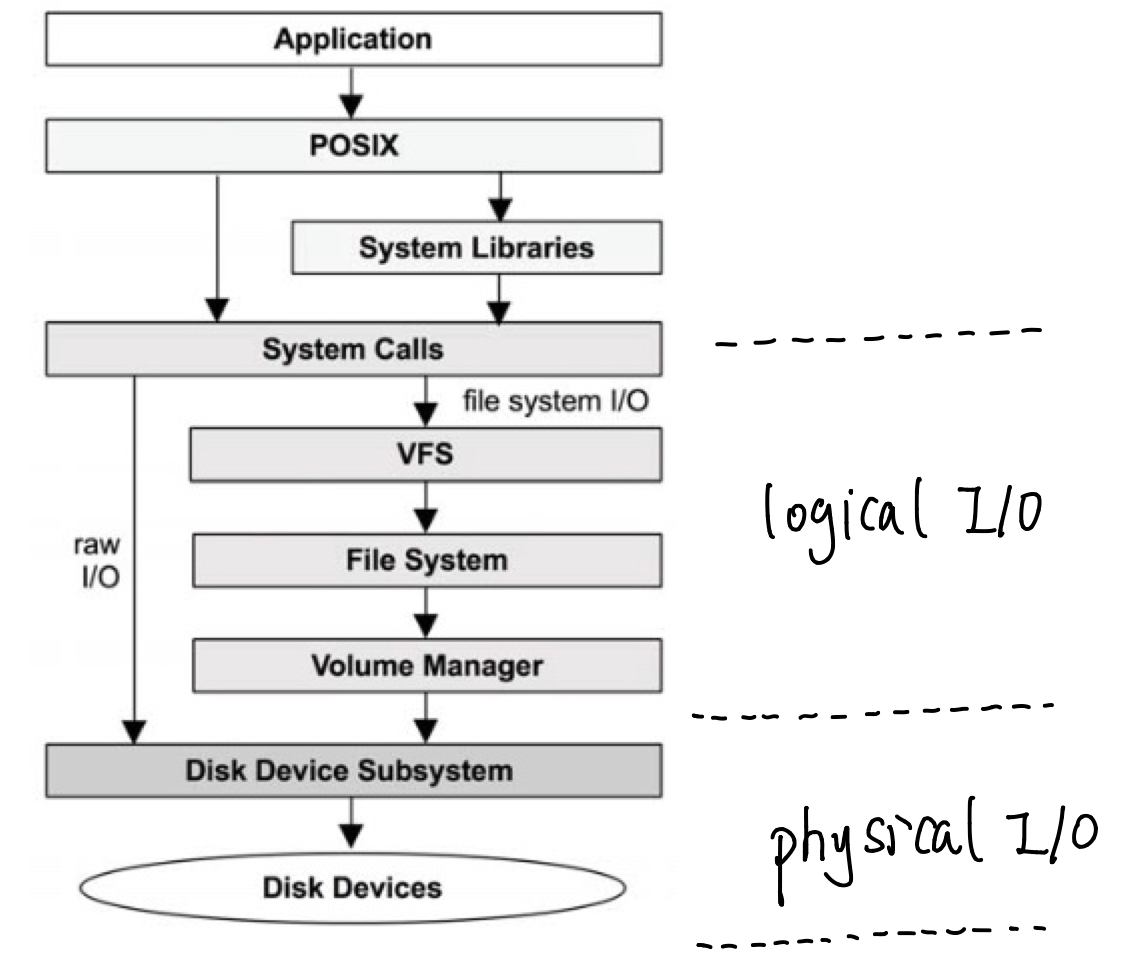 Figure 8-1 Generic I/O Stack
Figure 8-1 Generic I/O Stack
Logical I/O: describes requests to the file system.
Raw I/O: is rarely used nowadays: it is a way for applications to use disk devices with no file system.
8.1.2 File System Caches
Page cache: This contains virtual memory pages including the contents of files and I/O buffers (what was once a separate “buffer cache”), and improves the performance of file and directory I/O.
Inode cache: Inodes (index nodes) are data structures used by file systems to describe their stored objects. VFS has its own generic version of an inode, and Linux keeps a cache of these because they are frequently read for permission checks and other metadata.
Directory cache: caches mappings from directory entry names to VFS inodes, improving the performance of path name lookups.
8.1.3 Read Ahead
Read ahead improves read performance only for sequential access workloads.
8.1.4 Write Back
Buffers are dirtied in memory and flushed to disk sometime later by kernel worker threads, so as not to block applications directly on slow disk I/O.
8.1.5 BPF Capabilities
- What are the file system requests? Counts by type?
- What are the read sizes to the file system?
- How much write I/O was synchronous?
- What is the file workload access pattern: random or sequential?
- What files are accessed? By what process or code path? Bytes, I/O counts?
- What file system errors occurred? What type, and for whom?
- What is the source of file system latency? Is it disks, the code path, locks?
- What is the distribution of file system latency?
- What is the ratio of Dcache and Icache hits vs misses?
- What is the page cache hit ratio for reads?
- How effective is prefetch/read-ahead? Should this be tuned?
Event Sources
| I/O Type | Event Source |
|---|---|
| Application and library I/O | uprobes |
| System call I/O | syscalls tracepoints |
| File system I/O | ext4(…) tracepoints, kprobes |
| Cache hits (reads), write-back (writes) | kprobes |
| Cache misses (reads), write-through (writes) | kprobes |
| Page cache write-back | writeback tracepoints |
| Physical disk I/O | block tracepoints, kprobes |
| Raw I/O | kprobes |
ext4 provides over one hundred tracepoints.
Overhead
Logical I/O, especially reads and writes to the file system cache, can be very
frequent: over 100k events per second.
Physical disk I/O on most servers is typically so low (less than 1000 IOPS), that
tracing it incurs negligible overhead.
You can check the I/O rate beforehand with iostat.
8.1.6 Strategy
- Identify the mounted file systems: see
dfandmount. - Check the capacity of mounted file systems: there have been performance issues in the past, when certain file systems approach 100% full, due to the use of different free-block-finding algorithms (e.g., FFS, ZFS).
- Instead of using unfamiliar BPF tools to understand an unknown production
workload, first use those on a known workload. On an idle system, create a
known file system workload, e.g. using the
fiotool. - Run
opensnoopto see which files are being opened. - Run
filelifeto check for issues of short-lived files. - Look for unusually slow file system I/O, and examine process and file details
(e.g., using
ext4slower,btrfsslower,zfsslower, etc, or as a catch-all with possibly higher overhead,fileslower). It may reveal a workload that can be eliminated, or quantify a problem to aid file system tuning. - Examine the distribution of latency for your file systems (e.g., using
ext4dist,btrfsdist,zfsdist, etc). This may reveal bi-modal distributions or latency outliers that are causing performance problems, that can be isolated and investigated more with other tools. - Examine the page cache hit ratio over time (e.g., using
cachestat): does any other workload perturb the hit ratio, or does any tuning improve it? - Use
vfsstatto compare logical I/O rates to physical I/O rates fromiostat: ideally, there is a much higher rate of logical than physical I/O, indicating that caching is effective. - Browse and execute the BPF tools listed in the BPF tools section of this book.
8.2 TRADITIONAL TOOLS
8.2.1 df
# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 457M 328K 457M 1% /dev
tmpfs 457M 0 457M 0% /mnt
/dev/block/mmcblk0p2 0.9G 778M 230M 78% /system
/dev/block/mmcblk0p3 248M 13M 234M 6% /vendor
/dev/block/mmcblk0p4 2.3G 163M 2.2G 7% /data
/data/media 2.3G 163M 2.2G 7% /mnt/runtime/default/emulated
Once a file system exceeds about 90% full, it may begin to suffer performance issues as available free blocks become fewer and more scattered, turning sequential write workloads into random write workloads.
Or it may not: this is really dependent on the file system implementation.
8.2.2 mount
# mount
rootfs on / type rootfs (ro,seclabel)
tmpfs on /dev type tmpfs (rw,seclabel,nosuid,relatime,mode=755)
devpts on /dev/pts type devpts (rw,seclabel,relatime,mode=600,ptmxmode=000)
proc on /proc type proc (rw,relatime,gid=3009,hidepid=2)
sysfs on /sys type sysfs (rw,seclabel,relatime)
selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)
tmpfs on /mnt type tmpfs (rw,seclabel,nosuid,nodev,noexec,relatime,mode=755,gid=1000)
none on /acct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
none on /dev/memcg type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
debugfs on /sys/kernel/debug type debugfs (rw,seclabel,relatime,mode=755)
none on /config type configfs (rw,nosuid,nodev,noexec,relatime)
none on /dev/cpuctl type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
none on /dev/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset,noprefix,release_agent=/sbin/cpuset_release_agent)
cg2_bpf on /dev/cg2_bpf type cgroup2 (rw,nosuid,nodev,noexec,relatime)
/dev/block/mmcblk0p2 on /system type ext4 (ro,seclabel,relatime)
/dev/block/mmcblk0p3 on /vendor type ext4 (ro,seclabel,relatime)
/dev/block/mmcblk0p4 on /data type ext4 (rw,seclabel,nosuid,nodev,noatime,errors=panic)
tmpfs on /storage type tmpfs (rw,seclabel,nosuid,nodev,noexec,relatime,mode=755,gid=1000)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,seclabel,relatime)
/data/media on /mnt/runtime/default/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal)
/data/media on /storage/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal)
/data/media on /mnt/runtime/read/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=9997,multiuser,mask=23,derive_gid,default_normal)
/data/media on /mnt/runtime/write/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=9997,multiuser,mask=7,derive_gid,default_normal)
8.2.3 strace
strace has historically been implemented to use ptrace, which operates by
inserting breakpoints at the start and end of syscalls. This can massively slow
down target software, by as much as over 100 fold.
8.2.4 perf
perf trace
# perf stat -e 'ext4:*' -a
^C
Performance counter stats for 'system wide':
0 ext4:ext4_other_inode_update_time
0 ext4:ext4_free_inode
0 ext4:ext4_request_inode
0 ext4:ext4_allocate_inode
0 ext4:ext4_evict_inode
0 ext4:ext4_drop_inode
0 ext4:ext4_nfs_commit_metadata
20 ext4:ext4_mark_inode_dirty
1 ext4:ext4_begin_ordered_truncate
0 ext4:ext4_write_begin
7 ext4:ext4_da_write_begin
0 ext4:ext4_write_end
0 ext4:ext4_journalled_write_end
7 ext4:ext4_da_write_end
2 ext4:ext4_writepages
2 ext4:ext4_da_write_pages
1 ext4:ext4_da_write_pages_extent
2 ext4:ext4_writepages_result
0 ext4:ext4_writepage
0 ext4:ext4_readpage
0 ext4:ext4_releasepage
0 ext4:ext4_invalidatepage
0 ext4:ext4_journalled_invalidatepage
0 ext4:ext4_discard_blocks
0 ext4:ext4_mb_new_inode_pa
0 ext4:ext4_mb_new_group_pa
0 ext4:ext4_mb_release_inode_pa
0 ext4:ext4_mb_release_group_pa
4 ext4:ext4_discard_preallocations
0 ext4:ext4_mb_discard_preallocations
1 ext4:ext4_request_blocks
1 ext4:ext4_allocate_blocks
1 ext4:ext4_free_blocks
0 ext4:ext4_sync_file_enter
0 ext4:ext4_sync_file_exit
0 ext4:ext4_sync_fs
1 ext4:ext4_alloc_da_blocks
0 ext4:ext4_mballoc_alloc
1 ext4:ext4_mballoc_prealloc
0 ext4:ext4_mballoc_discard
1 ext4:ext4_mballoc_free
0 ext4:ext4_forget
1 ext4:ext4_da_update_reserve_space
3 ext4:ext4_da_reserve_space
0 ext4:ext4_da_release_space
0 ext4:ext4_mb_bitmap_load
0 ext4:ext4_mb_buddy_bitmap_load
0 ext4:ext4_read_block_bitmap_load
0 ext4:ext4_load_inode_bitmap
0 ext4:ext4_direct_IO_enter
0 ext4:ext4_direct_IO_exit
0 ext4:ext4_fallocate_enter
0 ext4:ext4_punch_hole
0 ext4:ext4_zero_range
0 ext4:ext4_fallocate_exit
0 ext4:ext4_unlink_enter
0 ext4:ext4_unlink_exit
1 ext4:ext4_truncate_enter
1 ext4:ext4_truncate_exit
0 ext4:ext4_ext_convert_to_initialized_enter
0 ext4:ext4_ext_convert_to_initialized_fastpath
2 ext4:ext4_ext_map_blocks_enter
0 ext4:ext4_ind_map_blocks_enter
2 ext4:ext4_ext_map_blocks_exit
0 ext4:ext4_ind_map_blocks_exit
0 ext4:ext4_ext_load_extent
0 ext4:ext4_load_inode
25 ext4:ext4_journal_start
[...]
15.203262026 seconds time elapsed
perf record -e ext4:ext4_da_write_begin -a
An equivalent version using bpftrace:
bpftrace -e 'tracepoint:ext4:ext4_da_write_begin { @ = hist(args->len); }'
8.2.5 fatrace
fatrace is a specialized tracer that uses the Linux fanotify API (file access notify).
fatrace can be used for workload characterization: understanding the files accessed, and looking for unnecessary work that could be eliminated.
However, for a busy file system workload, fatrace can produce tens of thousands of lines of output every second, and can cost significant CPU resources.
8.3 BPF TOOLS
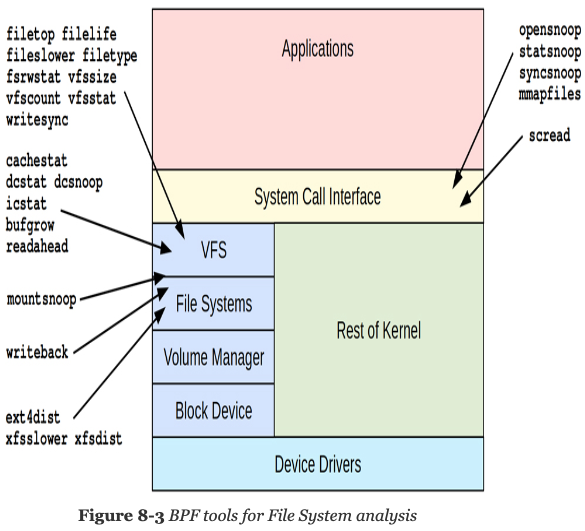
Table of File System-related tools
| Tools | Source | Target | overhead | Description |
|---|---|---|---|---|
| opensnoop | bcc/bt | Syscalls | negligible | Trace files opened |
| statsnoop | bcc/bt | Syscalls | negligible* | Trace calls to stat varieties |
| syncsnoop | bcc/bt | Syscalls | negligible | Trace sync and variety calls with timestamps |
| mmapfiles | book | Syscalls | negligible | Count mmap files |
| scread | book | Syscalls | Count read files | |
| fmapfault | book | Syscalls | noticeable | Count file map faults |
| filelife | bcc/book | VFS | negligible | Trace short-lived files with their lifespan in seconds |
| vfsstat | bcc/bt | VFS | measurable | Common VFS operation statistics |
| vfscount | bcc/bt | VFS | noticeable | Count all VFS operations |
| vfssize | bcc/bt | VFS | Show VFS read/write sizes | |
| fsrwstat | book | VFS | Show VFS reads/writes by file system type | |
| fileslower | bcc/book | VFS | higher | Show slow file reads/writes |
| filetop | bcc | VFS | noticeable | Top files in use by IOPS and bytes |
| filetype | book | VFS | Show VFS reads/writes by file type and process | |
| writesync | book | VFS | Show regular file writes by sync flag | |
| cachestat | bcc | Page cache | heavy | Page cache statistics |
| writeback | bt | Page cache | Show write-back events and latencies | |
| dcstat | bcc/book | Dcache | noticeable* | Directory cache hit statistics |
| dcsnoop | bcc/bt | Dcache | high | Trace directory cache lookups |
| mountsnoop | bcc | VFS | negligible | Trace mount and umounts system wide |
| xfsslower | bcc | XFS | noticeable* | Show slow XFS operations |
| xfsdist | bcc | XFS | Common XFS operation latency histograms | |
| ext4dist | bcc/book | ext4 | Common ext4 operation latency histograms | |
| icstat | book | Icache | Inode cache hit statistics | |
| bufgrow | book | Buffer cache | noticeable | Buffer cache growth by process and bytes |
| readahead | book | VFS | significant | Show read ahead hits and efficiency |
8.3.1 opensnoop
It can discover performance problems caused by frequent opens, or help troubleshoot issues caused by missing files.
If you find anything suspicious, further analysis can be done by tracking the stack trace of the process:
stackcount -p 3862 't:syscalls:sys_enter_openat'
The overhead is expected to be negligible as the open rate is typically infrequent.
opensnoop.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing open syscalls... Hit Ctrl-C to end.\n");
printf("%-6s %-16s %4s %3s %s\n", "PID", "COMM", "FD", "ERR", "PATH");
}
tracepoint:syscalls:sys_enter_open,
tracepoint:syscalls:sys_enter_openat
{
@filename[tid] = args->filename;
}
tracepoint:syscalls:sys_exit_open,
tracepoint:syscalls:sys_exit_openat
/@filename[tid]/
{
$ret = args->ret;
$fd = $ret > 0 ? $ret : -1;
$errno = $ret > 0 ? 0 : - $ret;
printf("%-6d %-16s %4d %3d %s\n", pid, comm, $fd, $errno,
str(@filename[tid]));
delete(@filename[tid]);
}
END
{
clear(@filename);
}
8.3.2 statsnoop
I found a number of occasions when stats were called tens of thousands of times
per second on production servers without a good reason; fortunately, it’s a fast
syscall, so these were not causing major performance issues. There was one exception,
however, where a Netflix microservice hit 100% disk utilization, which I found was
caused by a disk usage monitoring agent calling stat continually on a large file
system where the metadata did not fully cache, and the stat calls became disk I/O.
The overhead of this tool is expected to be negligible, unless the stat rate was very high.
statsnoop.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing stat syscalls... Hit Ctrl-C to end.\n");
printf("%-6s %-16s %3s %s\n", "PID", "COMM", "ERR", "PATH");
}
tracepoint:syscalls:sys_enter_statfs
{
@filename[tid] = args->pathname;
}
tracepoint:syscalls:sys_enter_statx,
tracepoint:syscalls:sys_enter_newstat,
tracepoint:syscalls:sys_enter_newlstat
{
@filename[tid] = args->filename;
}
tracepoint:syscalls:sys_exit_statfs,
tracepoint:syscalls:sys_exit_statx,
tracepoint:syscalls:sys_exit_newstat,
tracepoint:syscalls:sys_exit_newlstat
/@filename[tid]/
{
$ret = args->ret;
$errno = $ret >= 0 ? 0 : - $ret;
printf("%-6d %-16s %3d %s\n", pid, comm, $errno,
str(@filename[tid]));
delete(@filename[tid]);
}
END
{
clear(@filename);
}
8.3.3 syncsnoop
sync calls can trigger bursts of disk I/O, perturbing performance on the system.
The overhead of this tool is expected to be negligible, as the rate of sync is typically very infrequent.
syncsnoop.bt
BEGIN
{
printf("Tracing sync syscalls... Hit Ctrl-C to end.\n");
printf("%-9s %-6s %-16s %s\n", "TIME", "PID", "COMM", "EVENT");
}
tracepoint:syscalls:sys_enter_sync,
tracepoint:syscalls:sys_enter_syncfs,
tracepoint:syscalls:sys_enter_fsync,
tracepoint:syscalls:sys_enter_fdatasync,
tracepoint:syscalls:sys_enter_sync_file_range*,
tracepoint:syscalls:sys_enter_msync
{
time("%H:%M:%S ");
printf("%-6d %-16s %s\n", pid, comm, probe);
}
If sync related calls were found to be a problem, they can be examined further with custom bpftrace, showing the arguments and return value, and issued disk I/O.
8.3.4 mmapfiles
# ./mmapfiles.bt
Attaching 1 probe...
^C
@[lib, aarch64-linux-gnu, libvorbis.so.0.4.8]: 2
@[usr, bin, cat]: 2
@[lib, aarch64-linux-gnu, libcanberra.so.0.2.5]: 2
@[lib, aarch64-linux-gnu, libdl-2.30.so]: 2
@[lib, aarch64-linux-gnu, libm-2.30.so]: 2
@[lib, aarch64-linux-gnu, libpcre2-8.so.0.9.0]: 2
@[lib, aarch64-linux-gnu, libacl.so.1.1.2253]: 2
@[usr, bin, vim.basic]: 2
@[lib, aarch64-linux-gnu, libtdb.so.1.4.3]: 2
@[lib, aarch64-linux-gnu, libvorbisfile.so.3.3.7]: 2
@[lib, aarch64-linux-gnu, libogg.so.0.8.2]: 2
@[lib, aarch64-linux-gnu, libgpm.so.2]: 2
@[lib, aarch64-linux-gnu, libselinux.so.1]: 2
@[lib, aarch64-linux-gnu, libtinfo.so.6.2]: 2
@[lib, aarch64-linux-gnu, libpthread-2.30.so]: 2
@[lib, aarch64-linux-gnu, libltdl.so.7.3.1]: 2
@[lib, locale, locale-archive]: 10
@[usr, sbin, agetty]: 16
@[lib, aarch64-linux-gnu, libnss_files-2.30.so]: 18
@[/, etc, ld.so.cache]: 19
@[lib, aarch64-linux-gnu, ld-2.30.so]: 20
@[lib, aarch64-linux-gnu, libc-2.30.so]: 20
@[, , ]: 45
The last entry in the output above has no names: it is anonymous mappings for program private data.
Since the mmap() call is expected to be relatively infrequent, the overhead of this tool is expected to be negligible.
mmapfiles.bt
#!/usr/bin/bpftrace
#include <linux/mm.h>
kprobe:do_mmap {
$file = (struct file *)arg0;
$name = $file->f_path.dentry;
$dir1 = $name->d_parent;
$dir2 = $dir1->d_parent;
@[str($dir2->d_name.name), str($dir1->d_name.name),
str($name->d_name.name)] = count();
}
The aggregation key can be easily modified to include the process name, to show who is making these mappings (“@[comm, …]”), and the user-level stack as well to show the code path (“@[comm, ustack, …]”).
8.3.5 scread
scread.bt
#!/usr/bin/bpftrace
#include <linux/sched.h>
#include <linux/fs.h>
#include <linux/fdtable.h>
tracepoint:syscalls:sys_enter_read
{
$task = (struct task_struct *)curtask;
$file = (struct file *)*($task->files->fdt->fd + args->fd);
@filename[str($file->f_path.dentry->d_name.name)] = count();
}
File Descriptor to File Name
There are at least two ways to get file name from fd:
-
Walk from the task_struct to the file descriptor table, and use the FD as the index to find the struct file. The file name can then be found from this struct.
This is an unstable technique: the way the file descriptor table is found (task->files->fdt->fd) refers to kernel internals that may change between kernel versions.
-
Trace the open syscall(s), and build a lookup hash with the PID and FD as the keys, and the file/pathname as the value. This can then be queried during read and other syscalls. While this adds additional probes (and overhead), it is a stable technique.
Fetching file name by tracing via the VFS layer is much easier which provides the struct file immediately.
Another advantage of VFS tracing is that there is usually only one function per type of operation
8.3.6 fmapfault
fmapfault traces page faults for memory mapped files, and counts the process name and file name.
fmapfault.bt
#!/usr/bin/bpftrace
#include <linux/mm.h>
kprobe:filemap_fault
{
$vf = (struct vm_fault *)arg0;
$file = $vf->vma->vm_file->f_path.dentry->d_name.name;
@[comm, str($file)] = count();
}
The overhead of this tool may be noticeable for systems with high fault rates.
8.3.7 filelife
Used for tracing lifespan of short-lived files.
This tool has been used to find some small performance wins: discovering cases where applications were using temporary files which could be avoided. The overhead of this tool should be negligible as the rate of these should be relatively low.
filelife.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("%-6s %-16s %8s %s\n", "PID", "COMM", "AGE(ms)", "FILE");
}
kprobe:vfs_create,
kprobe:security_inode_create
{
@birth[arg1] = nsecs;
}
kprobe:vfs_unlink
/@birth[arg1]/
{
$dur = nsecs - @birth[arg1];
delete(@birth[arg1]);
$dentry = (struct dentry *) arg1;
printf("%-6d %-16s %8d %s\n", pid, comm, $dur / 1000000, str($dentry->d_name.name));
}
8.3.8 vfsstat
vfsstat provides the highest-level workload characterization of virtual file system operations.
# vfsstat
TIME READ/s WRITE/s FSYNC/s OPEN/s CREATE/s
02:41:23: 1715013 38717 0 5379 0
02:41:24: 947879 30903 0 10547 0
02:41:25: 1064800 34387 0 57883 0
02:41:26: 1150847 36104 0 5105 0
02:41:27: 1281686 33610 0 2703 0
02:41:28: 1075975 31496 0 6204 0
02:41:29: 868243 34139 0 5090 0
02:41:30: 889394 31388 0 2730 0
02:41:31: 1124013 35483 0 8121 0
17:21:47: 11443 7876 0 507 0
A surprising detail is the number of file opens per second: over five thousand. These are a slower operation, requiring path name lookups by the kernel and creating file descriptors, plus additional file metadata structs if they weren’t already cached. This workload can be investigated further using opensnoop to find ways to reduce the number of opens.
VFS functions can be very frequent, as shown by this real-world example and, at rates of over one million events per second, the overhead of this tool is expected to be measurable (e.g., 1-3% at this rate).
This tool is suited for ad hoc investigations, not 24x7 monitoring, where we’d prefer the overhead to be less than 0.1%.
This tool is only useful for the beginning of your investigation.
vfsstat.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing key VFS calls... Hit Ctrl-C to end.\n");
}
kprobe:vfs_read*,
kprobe:vfs_write*,
kprobe:vfs_fsync,
kprobe:vfs_open,
kprobe:vfs_create
{
@[func] = count();
}
interval:s:1
{
time();
print(@);
clear(@);
}
END
{
clear(@);
}
8.3.9 vfscount
# vfscount-bpfcc
Tracing... Ctrl-C to end.
^C
ADDR FUNC COUNT
ffff80001135dc88 b'vfs_setxattr' 3
ffff80001133b1e0 b'vfs_symlink' 3
ffff80001135d2e8 b'vfs_removexattr' 3
ffff800011339e28 b'vfs_unlink' 6
ffff80001133a398 b'vfs_rename' 6
ffff800011370b10 b'vfs_statfs' 7
ffff800011337d20 b'vfs_readlink' 9
ffff80001133b768 b'vfs_mkdir' 12
ffff800011339c50 b'vfs_rmdir' 12
ffff80001132a1c0 b'vfs_write' 86
ffff8000113b4238 b'vfs_lock_file' 204
ffff8000113258a8 b'vfs_open' 251
ffff800011330070 b'vfs_statx_fd' 260
ffff800011330128 b'vfs_statx' 261
ffff800011329f78 b'vfs_read' 462
ffff80001132fef8 b'vfs_getattr_nosec' 503
ffff800011330010 b'vfs_getattr' 503
The overhead of this tool, like vfsstat, can become noticeable at high rates of VFS calls.
vfscount.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing VFS calls... Hit Ctrl-C to end.\n");
}
kprobe:vfs_*
{
@[func] = count();
}
Its functionality can also be implemented using funccount, and bpftrace directly:
# funccount 'vfs_*'
# bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'
8.3.10 vfssize
# vfssize
Attaching 5 probes...
@[tomcat-exec-393, tomcat_access.log]:
[8K, 16K) 31 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[...]
@[grpc-default-wo, FIFO]:
[1] 266897 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
Processes named “grpc-default-wo” (truncated) did 266,897 one-byte reads or writes while tracing: this sounds like an opportunity for a performance optimization, by increasing the I/O size.
vfssize.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
@file[tid] = arg0;
}
kretprobe:vfs_read,
kretprobe:vfs_readv,
kretprobe:vfs_write,
kretprobe:vfs_writev
/@file[tid]/
{
if (retval >= 0) {
$file = (struct file *)@file[tid];
$name = $file->f_path.dentry->d_name.name;
if ((($file->f_inode->i_mode >> 12 ) & 15) == DT_FIFO) {
@[comm, "FIFO"] = hist(retval);
} else {
@[comm, str($name)] = hist(retval);
}
}
delete(@file[tid]);
}
END
{
clear(@file);
}
vfssize can be enhanced to include the type of call (read or write) by adding
“probe” as a key, the process ID (“pid”), and other details as desired.
@[comm, pid, probe, str($name)] = hist(retval);
8.3.11 fsrwstat
# ./fsrwstat.bt
Attaching 7 probes...
Tracing VFS reads and writes... Hit Ctrl-C to end.
08:27:04
@[devpts, vfs_write]: 2
@[sockfs, vfs_write]: 2
@[cgroup2, vfs_write]: 2
@[devtmpfs, vfs_read]: 2
@[cgroup, vfs_write]: 9
@[cgroup2, vfs_read]: 9
@[sysfs, vfs_read]: 10
@[anon_inodefs, vfs_read]: 11
@[tmpfs, vfs_write]: 14
@[ext4, vfs_read]: 16
@[proc, vfs_read]: 42
@[tmpfs, vfs_read]: 46
fsrwstat.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing VFS reads and writes... Hit Ctrl-C to end.\n");
}
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
@[str(((struct file *)arg0)->f_inode->i_sb->s_type->name), func] = count();
}
interval:s:1
{
time(); print(@); clear(@);
}
END
{
clear(@);
}
8.3.12 fileslower
Synchronous reads and writes are important as processes block on them and suffer their latency directly.
If fileslower shows a latency problem, it’s probably an actual problem.
Synchronous reads and writes will block a process. It is likely – but not certain – that this also causes application-level problems.
The current implementation (bcc version) traces all VFS reads and writes and then filters on those that are synchronous, so the overhead may be higher than expected.
fileslower.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("%-8s %-16s %-6s T %-7s %7s %s\n", "TIME(ms)", "COMM", "PID", "BYTES", "LAT(ms)", "FILE");
}
kprobe:new_sync_read,
kprobe:new_sync_write
{
$file = (struct file *)arg0;
if ($file->f_path.dentry->d_name.len != 0) {
@name[tid] = $file->f_path.dentry->d_name.name;
@size[tid] = arg2;
@start[tid] = nsecs;
}
}
kretprobe:new_sync_read
/@start[tid]/
{
$read_ms = (nsecs - @start[tid]) / 1000000;
if ($read_ms >= 10) {
printf("%-8d %-16s %-6d R %-7d %7d %s\n", nsecs / 1000000, comm, pid, @size[tid], $read_ms, str(@name[tid]));
}
delete(@start[tid]); delete(@size[tid]);
delete(@name[tid]);
}
kretprobe:new_sync_write
/@start[tid]/
{
$write_ms = (nsecs - @start[tid]) / 1000000;
if ($write_ms >= 10) {
printf("%-8d %-16s %-6d W %-7d %7d %s\n", nsecs / 1000000, comm, pid, @size[tid], $write_ms, str(@name[tid]));
}
delete(@start[tid]); delete(@size[tid]);
delete(@name[tid]);
}
END
{
clear(@start); clear(@size); clear(@name);
}
8.3.13 filetop
This tool is used for workload characterization and general file system observability. this may help you discover an unexpected I/O-busy file.
# filetop-bpfcc -C
Tracing... Output every 1 secs. Hit Ctrl-C to end
09:09:08 loadavg: 0.57 0.24 0.14 1/213 153640
TID COMM READS WRITES R_Kb W_Kb T FILE
153638 filetop-bpfcc 2 0 15 0 R loadavg
153638 filetop-bpfcc 1 0 4 0 R type
153638 filetop-bpfcc 1 0 4 0 R retprobe
153638 filetop-bpfcc 2 0 1 0 R _bootlocale.cpython-38.pyc
The overhead of this tool, like earlier ones, can begin to be noticeable because VFS reads/writes can be frequent. This also traces various statistics, including the file name, which makes its overhead a little higher than for other tools.
8.3.14 writesync
# ./writesync.bt
Attaching 3 probes...
Tracing VFS write sync flags... Hit Ctrl-C to end.
^C
@regular[gzip, auth.log.1.gz]: 1
@regular[rsync, .auth.log.PZEpg1]: 1
@regular[cron, loginuid]: 1
@regular[rsync, .wtmp.qsuCv1]: 1
@regular[rsync, .daemon.log.urEA4Z]: 1
@regular[systemd-journal, .#8:3207662oVbElg]: 1
@regular[rsync, .messages.nkXXk3]: 1
@regular[logrotate, status.tmp]: 1
@regular[gzip, btmp.1.gz]: 1
Synchronous writes must wait for the storage I/O to complete (write through), unlike normal I/O which can complete from cache (write-back). This makes synchronous I/O slow, and if the synchronous flag is unnecessary, removing it can greatly improve performance.
writesync.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
#include <asm-generic/fcntl.h>
BEGIN
{
printf("Tracing VFS write sync flags... Hit Ctrl-C to end.\n");
}
kprobe:vfs_write,
kprobe:vfs_writev
{
$file = (struct file *)arg0;
$name = $file->f_path.dentry->d_name.name;
if ((($file->f_inode->i_mode >> 12 ) & 15) == DT_REG) {
if ($file->f_flags & O_DSYNC) {
@sync[comm, str($name)] = count();
} else {
@regular[comm, str($name)] = count();
}
}
}
8.3.15 filetype
# ./filetype.bt
Attaching 5 probes...
Tracing VFS reads and writes... Hit Ctrl-C to end.
^C
@[other, vfs_read, systemd-journal]: 1
@[socket, vfs_read, sshd]: 1
@[character, vfs_write, sshd]: 1
@[other, vfs_read, systemd-udevd]: 1
@[character, vfs_write, filetype.bt]: 1
@[socket, vfs_write, (agetty)]: 1
@[regular, vfs_write, systemd-journal]: 1
@[other, vfs_read, systemd-logind]: 2
@[character, vfs_read, sshd]: 2
@[socket, vfs_write, sshd]: 2
@[regular, vfs_write, agetty]: 2
@[regular, vfs_read, filetype.bt]: 3
@[regular, vfs_write, systemd]: 4
@[other, vfs_read, systemd]: 8
@[regular, vfs_write, rs:main Q:Reg]: 9
@[regular, vfs_write, (agetty)]: 9
@[regular, vfs_read, (agetty)]: 10
@[regular, vfs_read, agetty]: 13
@[regular, vfs_read, systemd-journal]: 24
@[regular, vfs_read, systemd-logind]: 26
@[regular, vfs_read, systemd]: 48
filetype.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing VFS reads and writes... Hit Ctrl-C to end.\n");
// from uapi/linux/stat.h
@type[0xc000] = "socket";
@type[0xa000] = "link";
@type[0x8000] = "regular";
@type[0x6000] = "block";
@type[0x4000] = "directory";
@type[0x2000] = "character";
@type[0x1000] = "fifo";
@type[0] = "other";
}
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
$file = (struct file *)arg0;
$mode = $file->f_inode->i_mode;
@[@type[$mode & 0xf000], func, comm] = count();
}
END
{
clear(@type);
}
There is more than one way to write these tools, here is another version of filetype:
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing VFS reads and writes... Hit Ctrl-C to end.\n");
// from include/linux/fs.h
@type2str[0] = "UNKNOWN";
@type2str[1] = "FIFO";
@type2str[2] = "CHR";
@type2str[4] = "DIR";
@type2str[6] = "BLK";
@type2str[8] = "REG";
@type2str[10] = "LNK";
@type2str[12] = "SOCK";
@type2str[14] = "WHT";
}
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
$file = (struct file *)arg0;
$type = ($file->f_inode->i_mode >> 12 ) & 15;
@[@type2str[$type], func, comm] = count();
}
END
{
clear(@type2str);
}
8.3.16 cachestat
cachestat works by using kprobes to instrument these kernel functions:
- mark_page_accessed() for measuring cache accesses.
- mark_buffer_dirty() for measuring cache writes.
- add_to_page_cache_lru() for measuring page additions.
- account_page_dirtied() for measuring page dirties.
These page cache functions can be very frequent: they can be called millions of times a second. The overhead for this tool for extreme workloads can exceed 30%.
# cachestat
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
53401 2755 20953 95.09% 14 90223
49599 4098 21460 92.37% 14 90230
16601 2689 61329 86.06% 14 90381
15197 2477 58028 85.99% 14 90522
18169 4402 51421 80.50% 14 90656
57604 3064 22117 94.95% 14 90693
76559 3777 3128 95.30% 14 90692
49044 3621 26570 93.12% 14 90743
[...]
This output shows a hit ratio often exceeding 90%.
Tuning the system and application to bring this 90% close to 100% can result in very large performance wins (much larger than the 10% difference in hit ratio), as the application more often runs from memory without waiting on disk I/O.
In the following example, a 1GB file was created, the DIRTIES column shows pages being written to the page cache (“dirty”), and the CACHED_MB column increases by 1024 MB(1215-191):
# cachestat -T
TIME HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
21:06:47 0 0 0 0.00% 9 191*
21:06:48 0 0 120889 0.00% 9 663
21:06:49 0 0 141167 0.00% 9 1215*
21:06:50 795 0 1 100.00% 9 1215
21:06:51 0 0 0 0.00% 9 1215
The file is read between 21:09:08 and 21:09:48, seen by the high rate of MISSES, a low HITRATIO, and the increase in the page cache size in CACHED_MB by 1024 MB. At 21:10:08 the file was read the second time, now hitting entirely from the page cache (100%).
# cachestat -T 10
TIME HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
21:08:58 771 0 1 100.00% 8 190
21:09:08 33036 53975 16 37.97% 9 400
21:09:18 15 68544 2 0.02% 9 668
21:09:28 798 65632 1 1.20% 9 924
21:09:38 5 67424 0 0.01% 9 1187
21:09:48 3757 11329 0 24.90% 9 1232
21:09:58 2082 0 1 100.00% 9 1232
21:10:08 268421 11 12 100.00% 9 1232
21:10:18 6 0 0 100.00% 9 1232
21:10:19 784 0 1 100.00% 9 1232
8.3.17 writeback
# writeback.bt
Attaching 4 probes...
Tracing writeback... Hit Ctrl-C to end.
TIME DEVICE PAGES REASON ms
03:42:50 253:1 0 periodic 0.013
03:42:55 253:1 40 periodic 0.167
03:43:00 253:1 0 periodic 0.005
03:43:01 253:1 11268 background 6.112
03:43:01 253:1 11266 background 7.977
03:43:01 253:1 11314 background 22.209
03:43:02 253:1 11266 background 20.698
03:43:02 253:1 11266 background 7.421
03:43:02 253:1 11266 background 11.382
03:43:02 253:1 11266 background 6.954
03:43:02 253:1 11266 background 8.749
03:43:02 253:1 11266 background 14.518
03:43:04 253:1 38836 sync 64.655
03:43:04 253:1 0 sync 0.004
03:43:04 253:1 0 sync 0.002
03:43:09 253:1 0 periodic 0.012
03:43:14 253:1 0 periodic 0.016
[...]
There was a burst of background writebacks, writing tens of thousands of pages, and taking between 6 and 22 milliseconds for each writeback. This is asynchronous page flushing for when the system is running low on free memory.
The behavior of the write-back flushing is tunable (via vm.dirty_writeback_centisecs).
writeback.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing writeback... Hit Ctrl-C to end.\n");
printf("%-9s %-8s %-8s %-16s %s\n", "TIME", "DEVICE", "PAGES",
"REASON", "ms");
// see /sys/kernel/debug/tracing/events/writeback/writeback_start/format
@reason[0] = "background";
@reason[1] = "vmscan";
@reason[2] = "sync";
@reason[3] = "periodic";
@reason[4] = "laptop_timer";
@reason[5] = "free_more_memory";
@reason[6] = "fs_free_space";
@reason[7] = "forker_thread";
}
tracepoint:writeback:writeback_start
{
@start[args->sb_dev] = nsecs;
}
tracepoint:writeback:writeback_written
{
$sb_dev = args->sb_dev;
$s = @start[$sb_dev];
delete(@start[$sb_dev]);
$lat = $s ? (nsecs - $s) / 1000 : 0;
time("%H:%M:%S ");
printf("%-8s %-8d %-16s %d.%03d\n", args->name,
args->nr_pages & 0xffff, // TODO: explain these bitmasks
@reason[args->reason & 0xffffffff],
$lat / 1000, $lat % 1000);
}
END
{
clear(@reason);
clear(@start);
}
8.3.18 dcstat
This is the cache stat during kernel build:
# dcstat-bpfcc
TIME REFS/s SLOW/s MISS/s HIT%
13:51:57: 44567 101 18 99.96
13:51:58: 536552 109 15 100.00
13:51:59: 837607 13 0 100.00
13:52:00: 737675 184 100 99.99
13:52:01: 691790 58 0 100.00
13:52:02: 732677 42 0 100.00
13:52:03: 759888 43 1 100.00
13:52:04: 733796 58 1 100.00
13:52:05: 646478 69 2 100.00
13:52:06: 743152 40 0 100.00
13:52:07: 577740 92 0 100.00
13:52:08: 624744 74 0 100.00
13:52:09: 649661 45 0 100.00
13:52:10: 35679 143 103 99.71
- REFS/s: dcache references.
- SLOW/s: since Linux 2.5.11, the dcache has an optimization to avoid cacheline bouncing during lookups of common entries (“/”, “/usr”). This column shows when this optimization was not used, and the dcache lookup took the “slow” path.
- MISS/s: the dcache lookup failed. The directory entry may still be memory as part of the page cache, but the specialized dcache did not return it.
- HIT%: ratio of hits to reference
The overhead of this tool may become noticeable depending on the workload.
dcstat.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing dcache lookups... Hit Ctrl-C to end.\n");
printf("%10s %10s %5s\n", "REFS", "MISSES", "HIT%");
}
kprobe:lookup_fast { @hits++; }
kretprobe:d_lookup /retval == 0/ { @misses++; }
interval:s:1
{
$refs = @hits + @misses;
$percent = $refs > 0 ? 100 * @hits / $refs : 0;
printf("%10d %10d %4d%%\n", $refs, @misses, $percent);
clear(@hits);
clear(@misses);
}
END
{
clear(@hits);
clear(@misses);
}
8.3.19 dcsnoop
This tool is to trace directory entry cache (dcache) lookups, showing details on every lookup. The output can be verbose, thousands of lines per second, depending on the lookup rate.
The overhead of this tool is expected to be high for any moderate workload, as it is printing a line of output per event.
dcsnoop.bt
#!/usr/bin/env bpftrace
#include <linux/fs.h>
#include <linux/sched.h>
// from fs/namei.c:
struct nameidata {
struct path path;
struct qstr last;
// [...]
};
BEGIN
{
printf("Tracing dcache lookups... Hit Ctrl-C to end.\n");
printf("%-8s %-6s %-16s %1s %s\n", "TIME", "PID", "COMM", "T", "FILE");
}
// comment out this block to avoid showing hits:
kprobe:lookup_fast
{
$nd = (struct nameidata *)arg0;
printf("%-8d %-6d %-16s R %s\n", elapsed / 1000000, pid, comm,
str($nd->last.name));
}
kprobe:d_lookup
{
$name = (struct qstr *)arg1;
@fname[tid] = $name->name;
}
kretprobe:d_lookup
/@fname[tid]/
{
printf("%-8d %-6d %-16s M %s\n", elapsed / 1000000, pid, comm,
str(@fname[tid]));
delete(@fname[tid]);
}
8.3.20 mountsnoop
The overhead of this tool is expected to be negligible.
8.3.21 xfsslower
Similar to fileslower, this is instrumenting close to the application, and latency seen here is likely suffered by the application.
The overhead of this tool is relative to the rate of the operations, plus the rate of events printed that exceeded the threshold. The rate of operations for busy workloads can be high enough that the overhead is noticeable, even when there are no operations slower than the threshold so that no output is printed.
8.3.22 xfsdist
# xfsdist 10 1
Tracing XFS operation latency... Hit Ctrl-C to end.
23:55:23:
operation = 'read'
usecs : count distribution
0 -> 1 : 5492 |***************************** |
2 -> 3 : 4384 |*********************** |
4 -> 7 : 3387 |****************** |
8 -> 15 : 1675 |********* |
16 -> 31 : 7429 |****************************************|
32 -> 63 : 574 |*** |
64 -> 127 : 407 |** |
128 -> 255 : 163 | |
256 -> 511 : 253 |* |
512 -> 1023 : 98 | |
1024 -> 2047 : 89 | |
2048 -> 4095 : 39 | |
4096 -> 8191 : 37 | |
8192 -> 16383 : 27 | |
16384 -> 32767 : 11 | |
32768 -> 65535 : 21 | |
65536 -> 131071 : 10 | |
operation = 'write'
usecs : count distribution
0 -> 1 : 414 | |
2 -> 3 : 1327 | |
4 -> 7 : 3367 |** |
8 -> 15 : 22415 |************* |
16 -> 31 : 65348 |****************************************|
32 -> 63 : 5955 |*** |
64 -> 127 : 1409 | |
128 -> 255 : 28 | |
operation = 'open'
usecs : count distribution
0 -> 1 : 7557 |****************************************|
2 -> 3 : 263 |* |
4 -> 7 :4 | |
8 -> 15 :6 | |
16 -> 31 :2 | |
The read histogram shows a bi-modal distribution, with many taking less than seven microseconds, and another mode at 16 to 31 microseconds.
The speed of both these modes suggested they were served from the page cache. This difference between them may be caused by the size of the data read, or different types of reads that take different code paths.
The slowest reads reached the 65 to 131 millisecond bucket: these may be from storage devices, and also involve queueing.
The write histogram showed that most writes were in the 16 to 31 microsecond range: also fast, and likely using write-back buffering.
xfsdist.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing XFS operation latency... Hit Ctrl-C to end.\n");
}
kprobe:xfs_file_read_iter,
kprobe:xfs_file_write_iter,
kprobe:xfs_file_open,
kprobe:xfs_file_fsync
{
@start[tid] = nsecs;
@name[tid] = func;
}
kretprobe:xfs_file_read_iter,
kretprobe:xfs_file_write_iter,
kretprobe:xfs_file_open,
kretprobe:xfs_file_fsync
/@start[tid]/
{
@us[@name[tid]] = hist((nsecs - @start[tid]) / 1000);
delete(@start[tid]);
delete(@name[tid]);
}
END
{
clear(@start);
clear(@name);
}
8.3.23 ext4dist
# ext4dist-bpfcc
Tracing ext4 operation latency... Hit Ctrl-C to end.
^C
operation = read
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 6 |********************************** |
16 -> 31 : 7 |****************************************|
32 -> 63 : 1 |***** |
operation = open
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 3 |***************** |
16 -> 31 : 7 |****************************************|
32 -> 63 : 1 |***** |
# ./ext4dist.bt
Attaching 10 probes...
Tracing ext4 operation latency... Hit Ctrl-C to end.
^C
@us[ext4_file_open]:
[16, 32) 7 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32, 64) 4 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
@us[ext4_file_read_iter]:
[8, 16) 1 |@@@@ |
[16, 32) 12 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32, 64) 1 |@@@@ |
ext4dist.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing ext4 operation latency... Hit Ctrl-C to end.\n");
}
kprobe:ext4_file_read_iter,
kprobe:ext4_file_write_iter,
kprobe:ext4_file_open,
kprobe:ext4_sync_file
{
@start[tid] = nsecs;
@name[tid] = func;
}
kretprobe:ext4_file_read_iter,
kretprobe:ext4_file_write_iter,
kretprobe:ext4_file_open,
kretprobe:ext4_sync_file
/@start[tid]/
{
@us[@name[tid]] = hist((nsecs - @start[tid]) / 1000);
delete(@start[tid]);
delete(@name[tid]);
}
END
{
clear(@start);
clear(@name);
}
8.3.24 icstat
icstat traces inode cache references and misses, and prints statistics every second.
icstat.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing icache lookups... Hit Ctrl-C to end.\n");
printf("%10s %10s %5s\n", "REFS", "MISSES", "HIT%");
}
kretprobe:find_inode_fast
{
@refs++;
if (retval == 0) {
@misses++;
}
}
interval:s:1
{
$hits = @refs - @misses;
$percent = @refs > 0 ? 100 * $hits / @refs : 0;
printf("%10d %10d %4d%%\n", @refs, @misses, $percent);
clear(@refs);
clear(@misses);
}
END
{
clear(@refs);
clear(@misses);
}
8.3.25 bufgrow
This is a frequent function, so running this tool can cost noticeable overhead for busy workloads.
./bufgrow.bt
Attaching 2 probes...
Tracing buffer cache growth... Hit Ctrl-C to end.
^C
@kb[jbd2/mmcblk1p2-]: 152
bufgrow.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing buffer cache growth... Hit Ctrl-C to end.\n");
}
kprobe:add_to_page_cache_lru
{
$as = (struct address_space *)arg1;
$mode = $as->host->i_mode;
// match block mode, uapi/linux/stat.h
if ($mode & 0x6000) {
@kb[comm] = sum(4); // page size
}
}
8.3.26 readahead
# ./readahead.bt
Attaching 6 probes...
Tracing readahead... Hit Ctrl-C to end.
^C
Readahead unused pages: 433
Readahead used page age (ms):
@age_ms:
[1] 2455 |@@@@@@@@@@@@@@@ |
[2, 4) 8424 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4, 8) 4417 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 7680 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[16, 32) 4352 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 64) 0 | |
[64, 128) 0 | |
[128, 256) 384 |@@ |
The histogram shows thousands of pages were read and used, mostly within 32 milliseconds. If that time was in the many seconds, it could be a sign that readahead is loading too aggressively, and should be tuned.
Tracing page functions and storing extra metadata per page will likely add up to significant overhead, as these page functions are frequent. The overhead of this tool may reach 30% or higher on very busy systems. It is intended for short-term analysis.
readahead.bt
#!/usr/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing readahead... Hit Ctrl-C to end.\n");
}
kprobe:__do_page_cache_readahead
{
@in_readahead[tid] = 1;
}
kretprobe:__do_page_cache_readahead
{
@in_readahead[tid] = 0;
}
kretprobe:__page_cache_alloc
/@in_readahead[tid]/
{
@birth[retval] = nsecs;
@rapages++;
}
kprobe:mark_page_accessed
/@birth[arg0]/
{
@age_ms = hist((nsecs - @birth[arg0]) / 1000000);
delete(@birth[arg0]);
@rapages--;
}
END
{
printf("\nReadahead unused pages: %d\n", @rapages);
printf("\nReadahead used page age (ms):\n");
print(@age_ms); clear(@age_ms);
clear(@birth);
clear(@in_readahead);
clear(@rapages);
}
8.3.27 Other Tools
Other BPF tools worth mentioning:
- ext4slower, ext4dist
- btrfsslower, btrfsdist
8.4 BPF ONE-LINERS
Trace files opened via open(2) with process name:
opensnoop
bpftrace -e 't:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
Count read syscalls by syscall type:
funccount-bpfcc 't:syscalls:sys_enter_*read*'
bpftrace -e 'tracepoint:syscalls:sys_enter_*read* { @[probe] = count(); }'
Count write syscalls by syscall type:
funccount-bpfcc 't:syscalls:sys_enter_*write*'
bpftrace -e 'tracepoint:syscalls:sys_enter_*write* { @[probe] = count(); }'
Show the distribution of read() syscall request sizes:
argdist-bpfcc -H 't:syscalls:sys_enter_read():int:args->count'
bpftrace -e 'tracepoint:syscalls:sys_enter_read { @ = hist(args->count); }'
Show the distribution of read() syscall read bytes (and errors):
argdist-bpfcc -H 't:syscalls:sys_exit_read():int:args->ret'
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ = hist(args->ret); }'
Count read() syscall errors by error code:
argdist-bpfcc -C 't:syscalls:sys_exit_read():int:args->ret:args->ret<0'
bpftrace -e 't:syscalls:sys_exit_read /args->ret < 0/ { @[- args->ret] = count(); }'
Count VFS calls:
funccount-bpfcc 'vfs_*'
bpftrace -e 'kprobe:vfs_* { @[probe] = count(); }'
Count ext4 tracepoints:
funccount-bpfcc 't:ext4:*'
bpftrace -e 'tracepoint:ext4:* { @[probe] = count(); }'
Count ext4 file reads by process name and stack trace:
stackcount-bpfcc ext4_file_read_iter
Count ext4 file reads by process name:
bpftrace -e 'kprobe:ext4_file_read_iter { @[comm] = count(); }'
Count ext4 file reads by process name and user-level stack only:
stackcount-bpfcc -U ext4_file_read_iter
bpftrace -e 'kprobe:ext4_file_read_iter { @[ustack, comm] = count(); }'
Count dcache references by process name and PID:
bpftrace -e 'kprobe:lookup_fast { @[comm, pid] = count(); }'
Count FS reads to storage devices via read_pages, with stacks and process names:
stackcount-bpfcc -P read_pages
Count FS reads to storage devices via read_pages, with kernel stacks:
bpftrace -e 'kprobe:read_pages { @[kstack] = count(); }'
Count ext4 reads to storage devices, with stacks and process names:
stackcount-bpfcc -P ext4_readpages
Count ext4 reads to storage devices via read_pages, with kernel stacks:
bpftrace -e 'kprobe:ext4_readpages { @[kstack] = count(); }'
8.5 BPF ONE-LINERS EXAMPLES
Show the distribution of read() syscall read bytes (and errors)
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ = hist(args->ret); }'
Reads returned one byte only could be a target for performance optimizations. These can be investigated further by fetching the stack for these one-byte reads like this:
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret == 1/ { @[ustack] = count(); }'
8.6 OPTIONAL EXERCISES
- Rewrite filelife to use the syscall tracepoints for creat and unlink.
- What are the pros and cons of switching filelife to these tracepoints?
- Develop a version of vfsstat that prints separate rows for your local file system and TCP. (See vfssize and fsrwstat.)
- Develop a tool to show the ratio of logical file system I/O (via VFS or the file system interface) vs physical I/O (via block tracepoints).
- Develop a tool to analyze file descriptor leaks: those that were allocated during tracing but not freed. One possible solution may be to trace the kernel functions __alloc_fd() and __close_fd().
- (Advanced) Develop a tool to show file system I/O broken down by mountpoint.
- (Advanced, unsolved) Develop a tool to show the time between accesses in the page cache as a distribution. What are the challenges with this tool?
Chapter 9. Disk I/O
Learning objectives:
- Understand the I/O stack and the role of Linux I/O schedulers.
- Learn a strategy for successful analysis of disk I/O performance.
- Identify issues of disk I/O latency outliers.
- Analyze multi-modal disk I/O distributions.
- Identify which code paths are issuing disk I/O, and their latency.
- Analyze I/O scheduler latency.
- Use bpftrace one-liners to explore disk I/O in custom ways.
9.1 BACKGROUND
9.1.1 Block I/O Stack
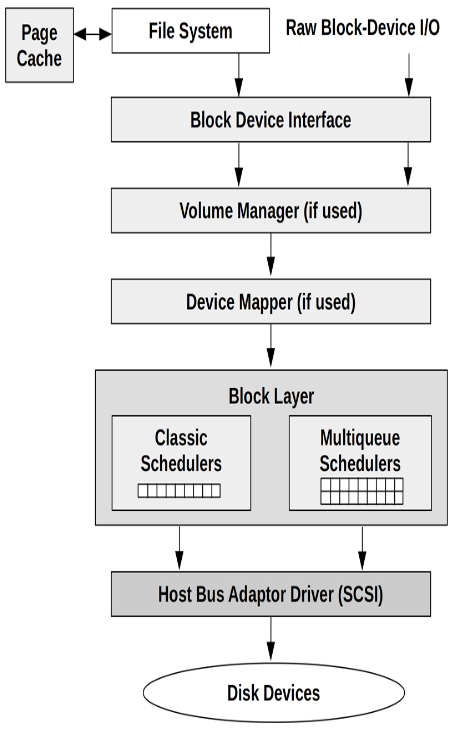
Figure 9-1 Linux block I/O stack
The term block I/O refers to device access in blocks, traditionally 512-byte sectors. The block device interface originated from Unix. Linux has enhanced block I/O with the addition of schedulers for improving I/O performance, volume managers for grouping multiple devices, and a device mapper for creating virtual devices.
Internals
- struct request (from include/linux/blkdev.h)
- struct bio (from include/linux/blk_types.h).
rwbs
- R: Read
- W: Write
- M: Metadata
- S: Synchronous
- A: Read-ahead
- F: Flush or Force Unit Access
- D: Discard
- E: Erase
- N: None
9.1.2 I/O Schedulers
The classic schedulers are:
- Noop: No scheduling (a no-operation).
- Deadline: Enforce a latency deadline, useful for real-time systems.
- CFQ: The completely fair queueing scheduler, which allocates I/O time slices to processes, similar to CPU scheduling.
The multi-queue driver (blk-mq, added in Linux 3.13) solves this by using separate submission queues for each CPU, and multiple dispatch queues for the devices.
Multi-queue schedulers available include:
- None: No queueing.
- BFQ: The budget fair queueing scheduler, similar to CFQ, but it allocates bandwidth as well as I/O time.
- mq-deadline: a blk-mq version of deadline.
- Kyber: A scheduler that adjusts read and write dispatch queue lengths based on performance, so that target read or write latencies can be met.
The classic schedulers and the legacy I/O stack were removed in Linux 5.0.
9.1.3 Disk I/O Performance
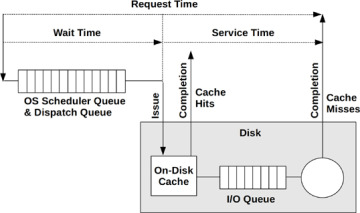
9.1.4 BPF Capabilities
- What are the disk I/O requests? What type, how many, and what I/O size?
- What were the request times? Queued times?
- Were there latency outliers?
- Is the latency distribution multi-modal?
- Were there any disk errors?
- What SCSI commands were sent?
- Were there any timeouts?
9.1.5 Event Sources
| Event Type | Event Sources |
|---|---|
| block interface and block layer I/O | block tracepoints, kprobes |
| I/O scheduler events | kprobes |
| SCSI I/O | scsi tracepoints, kprobes |
| Device driver I/O | kprobes |
# bpftrace -lv tracepoint:block:block_rq_issue
tracepoint:block:block_rq_issue
dev_t dev;
sector_t sector;
unsigned int nr_sector;
unsigned int bytes;
char rwbs[8];
char comm[16];
__data_loc char[] cmd;
One-liner to tell I/O size of the requests:
# bpftrace -e 'tracepoint:block:block_rq_issue { @bytes = hist(args->bytes); }'
Attaching 1 probe...
^C
@bytes:
[0] 2 | |
[1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 0 | |
[16, 32) 0 | |
[32, 64) 0 | |
[64, 128) 0 | |
[128, 256) 0 | |
[256, 512) 0 | |
[512, 1K) 0 | |
[1K, 2K) 0 | |
[2K, 4K) 0 | |
[4K, 8K) 1216 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8K, 16K) 364 |@@@@@@@ |
[16K, 32K) 2392 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32K, 64K) 551 |@@@@@@@@@@@ |
[64K, 128K) 4 | |
[128K, 256K) 8 | |
9.1.6 Strategy
- For application performance issues, begin with file system analysis.
- Check basic disk metrics: request times, IOPS, and utilization. (e.g., iostat).
Look for high utilization (which is a clue) and higher than normal request times
(latency) and IOPS.
- If you are unfamiliar with what IOPS rates or latencies are normal, use a microbenchmark tool such as fio on an idle system with some known workloads, and run iostat to examine them.
- Trace block I/O latency distributions and check for multi-modal distributions and latency outliers (e.g., using biolatency).
- Trace individual block I/O and look for patterns such as reads queueing behind writes (you can use biosnoop).
- Use other tools and one-liners from this chapter.
9.2 TRADITIONAL TOOLS
9.2.1 iostat
The statistics it sources are maintained by the kernel by default, so the overhead of this tool is considered negligible.
$ iostat -dxz 1
Linux 5.7.8+ (arm-64) 09/24/2020 _aarch64_ (8 CPU)
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk1 0.38 12.52 0.04 9.38 1.15 32.55 0.17 6.20 0.24 58.89 21.75 37.18 0.00 0.00 0.00 0.00 0.00 0.00 0.02 1.93 0.00 0.09
mmcblk1boot0 0.00 0.00 0.00 0.00 1.12 4.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
mmcblk1boot1 0.00 0.00 0.00 0.00 1.03 4.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.21 0.00 8.89 4.93 54.20 0.00 0.13 0.03 86.25 2.93 29.09 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[...]
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk1 1196.00 18096.00 0.00 0.00 0.36 15.13 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.43 90.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk1 1570.00 20504.00 0.00 0.00 0.33 13.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.51 99.60
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
mmcblk1 1087.00 50824.00 0.00 0.00 0.65 46.76 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.71 100.00
Commonly used options are:
-d Display disk utilization.
-t Print the time for each report displayed.
-x Display extended statistics.
-z Skipping devices with zero metrics.
- r/s: read requests completed per second (after merges).
- rkB/s: Kbytes read from the disk device per second.
- rrqm/s: read requests queued and merged per second.
- r_await: same as await, but for reads only (ms).
- rareq-sz: read average request size.
- w/s: write requests completed per second (after merges).
- wkB/s: Kbytes written to the disk device per second.
- wrqm/s: write requests queued and merged per second.
- w_await: same as await, but for writes only (ms).
- wareq-sz: write average request size.
- avgqu-sz: average number of requests both waiting in the driver request queue and active on the device.
- %util: percent of time device was busy processing I/O requests (utilization).
9.2.2 perf
Tracing the queuing of requests (block_rq_insert), their issue to a storage device (block_rq_issue), and their completions (block_rq_complete):
# perf record -e block:block_rq_insert,block:block_rq_issue,block:block_rq_complete -a
^C[ perf record: Woken up 12 times to write data ]
[ perf record: Captured and wrote 4.014 MB perf.data (33281 samples) ]
# perf script
aarch64-linux-g 104602 [007] 438172.654210: block:block_rq_issue: 179,0 RA 12288 () 24811944 + 24 [aarch64-linux-g]
swapper 0 [007] 438172.654609: block:block_rq_complete: 179,0 RA () 24811944 + 24 [0]
aarch64-linux-g 104602 [007] 438172.655219: block:block_rq_issue: 179,0 RA 4096 () 28310456 + 8 [aarch64-linux-g]
swapper 0 [007] 438172.655491: block:block_rq_complete: 179,0 RA () 28310456 + 8 [0]
aarch64-linux-g 104602 [007] 438172.655620: block:block_rq_issue: 179,0 RA 4096 () 28310792 + 8 [aarch64-linux-g]
aarch64-linux-g 104602 [007] 438172.655680: block:block_rq_issue: 179,0 RA 4096 () 28310840 + 8 [aarch64-linux-g]
ksoftirqd/7 46 [007] 438172.655847: block:block_rq_complete: 179,0 RA () 28310792 + 8 [0]
swapper 0 [007] 438172.656016: block:block_rq_complete: 179,0 RA () 28310840 + 8 [0]
9.2.3 blktrace
btrace is a shell wrapper of blktrace.
# btrace /dev/sda5
8,5 4 1 0.000000000 0 C RM 1370007616 + 8 [0]
8,5 4 0 0.000011597 0 m N served: vt=608275634835238912 min_vt=608275459292385280
8,5 4 0 0.000031376 0 m N cfq208A Not idling. st->count:1
8,0 4 2 0.000104784 16544 A RM 1379655560 + 8 <- (8,5) 278605704
8,5 4 3 0.000105340 16544 Q RM 1379655560 + 8 [make]
8,5 4 4 0.000108474 16544 G RM 1379655560 + 8 [make]
8,5 4 5 0.000108987 16544 I RM 1379655560 + 8 [make]
8,5 5 642 0.582417088 691 Q WS 1525010512 + 8 [jbd2/sda5-8]
8,5 5 643 0.582417256 691 M WS 1525010512 + 8 [jbd2/sda5-8]
8,0 5 644 0.582417438 691 A WS 1525010520 + 8 <- (8,5) 423960664
8,5 5 645 0.582417530 691 Q WS 1525010520 + 8 [jbd2/sda5-8]
8,5 5 646 0.582417668 691 M WS 1525010520 + 8 [jbd2/sda5-8]
The columns are:
- Device major, minor number
- CPU ID
- Sequence number
- Action time, in seconds
- Process ID
-
Action identifier: see blkparse.
Action Description C completed D issued I inserted Q queued B bounced M merge G get request F front merge S sleep P plug U unplug T unplug due to timer X split A remap - RWBS description
- Address + size [device].
As with perf per-event dumping, the overhead of blktrace can be a problem for busy disk I/O workloads.
For using blktrace CONFIG_BLK_DEV_IO_TRACE need to be enabled, and the following
options are also enabled:
CONFIG_NOP_TRACER=y
CONFIG_EVENT_TRACING=y
CONFIG_CONTEXT_SWITCH_TRACER=y
CONFIG_TRACING=y
CONFIG_GENERIC_TRACER=y
CONFIG_BINARY_PRINTF=y
This impact performance, and should be enabled only for debug config.
9.2.4 SCSI log
# sysctl -w dev.scsi.logging_level=0x1b6db6db
# echo 0x1b6db6db > /proc/sys/dev/scsi/logging_level
Depending on your disk workload, this may flood your system log.
9.3 BPF TOOLS
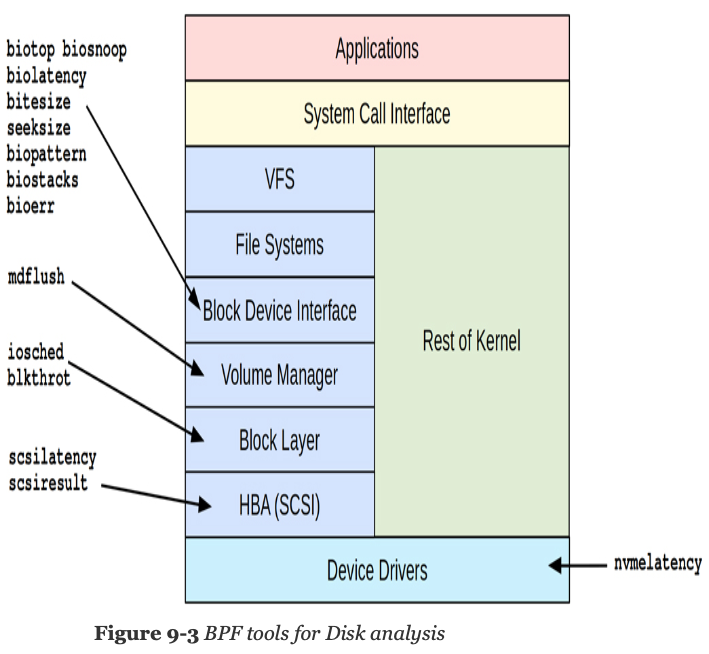
| Tool | Source | Target | Overhead | Description |
|---|---|---|---|---|
| biolatency | bcc/bt | Block I/O | negligible | Summarize block I/O latency as histogram |
| biosnoop | bcc/bt | Block I/O | little higher | Trace block I/O with PID and latency |
| biotop | bcc | Block I/O | negligible | Top for disks: summarize block I/O by process |
| bitesize | bcc/bt | Block I/O | Show disk I/O size histogram by process | |
| seeksize | book | Block I/O | Show requested I/O seek distances | |
| biopattern | book | Block I/O | Identify random/sequential disk access patterns | |
| biostacks | book | Block I/O | Show disk I/O with initialization stacks | |
| bioerr | book | Block I/O | Trace disk errors | |
| iosched | book | I/O Sched | Summarize I/O scheduler latency | |
| scsilatency | book | SCSI | Show SCSI command latency distributions | |
| scsiresult | book | SCSI | Show SCSI command result codes |
9.3.1 biolatency
biolatency is a tool to show block I/O device latency as a histogram. The term device latency refers to the time from issuing a request to the device, to when it completes, including time spent queued in the operating system.
The biolatency tool currently works by tracing various block I/O kernel functions using kprobes. The overhead of this tool should be negligible on most systems where the disk IOPS rate is low (<1000).
# biolatency-bpfcc 10 1
Tracing block device I/O... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 1 | |
128 -> 255 : 1150 |************************* |
256 -> 511 : 1802 |****************************************|
512 -> 1023 : 1393 |****************************** |
1024 -> 2047 : 433 |********* |
2048 -> 4095 : 21 | |
4096 -> 8191 : 31 | |
8192 -> 16383 : 48 |* |
16384 -> 32767 : 40 | |
32768 -> 65535 : 45 | |
Queued Time
BCC biolatency has a -Q option to include the OS queued time:
# biolatency-bpfcc -Q 10 1
Tracing block device I/O... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 0 | |
128 -> 255 : 1755 |****************** |
256 -> 511 : 3793 |****************************************|
512 -> 1023 : 2094 |********************** |
1024 -> 2047 : 843 |******** |
2048 -> 4095 : 20 | |
4096 -> 8191 : 1 | |
8192 -> 16383 : 2 | |
16384 -> 32767 : 1 | |
Disks
The -D option in biolatency shows histograms for disks separately:
# biolatency-bpfcc -D 10 1
Tracing block device I/O... Hit Ctrl-C to end.
disk = b'mmcblk1'
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 0 | |
128 -> 255 : 99 |*** |
256 -> 511 : 1096 |****************************************|
512 -> 1023 : 734 |************************** |
1024 -> 2047 : 705 |************************* |
2048 -> 4095 : 34 |* |
4096 -> 8191 : 110 |**** |
8192 -> 16383 : 81 |** |
16384 -> 32767 : 106 |*** |
32768 -> 65535 : 167 |****** |
65536 -> 131071 : 4 | |
Flags
BCC biolatency also has a -F option to print each set of I/O flags differently.
# biolatency-bpfcc -Fm 10 1
Tracing block device I/O... Hit Ctrl-C to end.
flags = ReadAhead-Read
msecs : count distribution
0 -> 1 : 2275 |****************************************|
2 -> 3 : 16 | |
4 -> 7 : 53 | |
8 -> 15 : 10 | |
16 -> 31 : 72 |* |
32 -> 63 : 2 | |
flags = Background-Priority-Metadata-Write
msecs : count distribution
0 -> 1 : 3 |****************************************|
flags = NoMerge-Write
msecs : count distribution
0 -> 1 : 1 | |
2 -> 3 : 1 | |
4 -> 7 : 60 |********************************** |
8 -> 15 : 65 |************************************* |
16 -> 31 : 69 |****************************************|
32 -> 63 : 43 |************************ |
64 -> 127 : 2 |* |
flags = Flush
msecs : count distribution
0 -> 1 : 2 |****************************************|
flags = Sync-Write
msecs : count distribution
0 -> 1 : 2 |****************************************|
flags = Write
msecs : count distribution
0 -> 1 : 20 |****************************************|
2 -> 3 : 16 |******************************** |
4 -> 7 : 14 |**************************** |
8 -> 15 : 4 |******** |
16 -> 31 : 16 |******************************** |
32 -> 63 : 4 |******** |
flags = ForcedUnitAccess-Sync-Write
msecs : count distribution
0 -> 1 : 2 |****************************************|
flags = Read
msecs : count distribution
0 -> 1 : 2 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 2 |****************************************|
Using an interval of one will print per-second histograms. This information can be visualized as a latency heat map, with a full second as columns, latency ranges as rows, and a color saturation to show the number of I/O in that time range.
biolatency.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing block device I/O... Hit Ctrl-C to end.\n");
}
kprobe:blk_account_io_start
{
@start[arg0] = nsecs;
}
kprobe:blk_account_io_done
/@start[arg0]/
{
@usecs = hist((nsecs - @start[arg0]) / 1000);
delete(@start[arg0]);
}
END
{
clear(@start);
}
9.3.2 biosnoop
biosnoop is a BCC and bpftrace tool that prints a one-line summary for each disk I/O.
# biosnoop-bpfcc
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
0.000000 aarch64-linux- 118867 mmcblk1 R 28657896 8192 0.32
0.001271 aarch64-linux- 118867 mmcblk1 R 28657120 32768 0.49
0.001407 aarch64-linux- 118867 mmcblk1 R 28657352 4096 0.53
0.001844 aarch64-linux- 118867 mmcblk1 R 28657360 16384 0.29
0.002188 aarch64-linux- 118867 mmcblk1 R 28657520 4096 0.17
0.002687 aarch64-linux- 118867 mmcblk1 R 28657528 16384 0.30
0.004096 aarch64-linux- 118867 mmcblk1 R 28528896 8192 0.37
The overhead of this tool is a little higher than biolatency as it is printing per-event output.
OS Queued Time
A -Q option to BCC biosnoop can be used to show the time spent between the creation
of the I/O and the issue to the device: this time is mostly spent on OS queues, but
could also include memory allocation and lock acquisition.
# biosnoop-bpfcc -Q
TIME(s) COMM PID DISK T SECTOR BYTES QUE(ms) LAT(ms)
0.000000 aarch64-linux- 121836 mmcblk1 R 24390032 16384 0.04 0.36
0.000347 aarch64-linux- 121836 mmcblk1 R 24390320 4096 0.02 0.19
0.000628 aarch64-linux- 121836 mmcblk1 R 24390328 4096 0.02 0.17
0.001177 aarch64-linux- 121836 mmcblk1 R 24390112 4096 0.02 0.19
0.001711 aarch64-linux- 121836 mmcblk1 R 24390120 16384 0.02 0.35
Note that earlier I/O lacked most of the column details: they were enqueued before tracing began, and so biosnoop missed caching those details, and only shows the device latency.
bpftrace version of biosnoop traces the full duration of the I/O, including queued time.
biosnoop.bt
#!/usr/bin/env bpftrace
BEGIN
{
printf("%-12s %-16s %-6s %7s\n", "TIME(ms)", "COMM", "PID", "LAT(ms)");
}
kprobe:blk_account_io_start
{
@start[arg0] = nsecs;
@iopid[arg0] = pid;
@iocomm[arg0] = comm;
}
kprobe:blk_account_io_done
/@start[arg0] != 0 && @iopid[arg0] != 0 && @iocomm[arg0] != ""/
{
$now = nsecs;
printf("%-12u %-16s %-6d %7d\n",
elapsed / 1000000, @iocomm[arg0], @iopid[arg0],
($now - @start[arg0]) / 1000000);
delete(@start[arg0]);
delete(@iopid[arg0]);
delete(@iocomm[arg0]);
}
END
{
clear(@start);
clear(@iopid);
clear(@iocomm);
}
9.3.3 biotop
biotop is a BCC tool that is top for disks.
# biotop-bpfcc -C
Tracing... Output every 1 secs. Hit Ctrl-C to end
11:07:10 loadavg: 1.79 0.47 0.27 2/221 125071
PID COMM D MAJ MIN DISK I/O Kbytes AVGms
125069 aarch64-linux-g R 179 0 mmcblk1 458 18528.0 0.53
11:07:11 loadavg: 1.79 0.47 0.27 1/221 125071
PID COMM D MAJ MIN DISK I/O Kbytes AVGms
125069 aarch64-linux-g R 179 0 mmcblk1 257 13612.0 0.95
115770 kworker/u16:0 W 179 0 mmcblk1 85 9948.0 10.87
720 NetworkManager R 179 0 mmcblk1 7 400.0 1.30
300 jbd2/mmcblk1p2- W 179 0 mmcblk1 2 36.0 0.37
720 NetworkManager W 179 0 mmcblk1 1 4.0 0.15
115770 kworker/u16:0 R 179 0 mmcblk1 1 4.0 1.98
biotop using the same events as biolatency, with similar overhead expectations.
9.3.4 bitesize
bitesize is a tool to show the size of disk I/O.
# bitesize-bpfcc
Tracing block I/O... Hit Ctrl-C to end.
^C
Process Name = kworker/7:0H
Kbytes : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 0 | |
128 -> 255 : 1 |****************************************|
Process Name = aarch64-linux-g
Kbytes : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 931 |************************* |
8 -> 15 : 350 |********* |
16 -> 31 : 899 |************************ |
32 -> 63 : 1441 |****************************************|
64 -> 127 : 1202 |********************************* |
128 -> 255 : 859 |*********************** |
Process Name = jbd2/mmcblk1p2-
Kbytes : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 1 |****************************************|
Checking the I/O size can lead to optimizations:
- Sequential workloads should try the largest possible I/O size for peak performance. Larger sizes sometimes encounter slightly worse performance; there may be a sweet spot (e.g., 128 Kbytes) based on memory allocators and device logic.
- Random workloads should try to match the I/O size with the application record size. Larger I/O sizes pollute the page cache with data that isn’t needed; smaller I/O sizes result in more I/O overhead than needed.
This works by instrumenting the block:block_rq_issue tracepoint.
This is a bpftrace version of the bitesize.bt:
#!/usr/bin/env bpftrace
BEGIN
{
printf("Tracing block device I/O... Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_issue
{
@[args->comm] = hist(args->bytes);
}
END
{
printf("\nI/O size (bytes) histograms by process name:");
}
9.3.5 seeksize
seeksize is a bpftrace tool to show how many sectors that processes are requesting the disks to seek.
# ./seeksize.bt
Attaching 3 probes...
Tracing block I/O requested seeks... Hit Ctrl-C to end.
^C
[...]
@sectors[kworker/4:0H]:
(..., 0) 11 |@@@@@@@@@@@@@@@@@@@@@@ |
[0] 0 | |
[1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 26 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 32) 17 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 64) 14 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[64, 128) 7 |@@@@@@@@@@@@@@ |
[128, 256) 5 |@@@@@@@@@@ |
[256, 512) 2 |@@@@ |
[512, 1K) 4 |@@@@@@@@ |
[1K, 2K) 2 |@@@@ |
[2K, 4K) 3 |@@@@@@ |
[4K, 8K) 2 |@@@@ |
[8K, 16K) 1 |@@ |
[16K, 32K) 0 | |
[32K, 64K) 2 |@@@@ |
[64K, 128K) 0 | |
[128K, 256K) 0 | |
[256K, 512K) 0 | |
[512K, 1M) 2 |@@@@ |
[1M, 2M) 0 | |
[2M, 4M) 4 |@@@@@@@@ |
[4M, 8M) 4 |@@@@@@@@ |
[8M, 16M) 4 |@@@@@@@@ |
@sectors[kworker/2:0H]:
(..., 0) 23 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[0] 28 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 10 |@@@@@@@@@@@@@@@@@@ |
[16, 32) 9 |@@@@@@@@@@@@@@@@ |
[32, 64) 4 |@@@@@@@ |
[64, 128) 7 |@@@@@@@@@@@@@ |
[128, 256) 4 |@@@@@@@ |
[256, 512) 5 |@@@@@@@@@ |
[512, 1K) 2 |@@@ |
[1K, 2K) 0 | |
[2K, 4K) 0 | |
[4K, 8K) 5 |@@@@@@@@@ |
[8K, 16K) 1 |@ |
[16K, 32K) 1 |@ |
[32K, 64K) 1 |@ |
[64K, 128K) 0 | |
[128K, 256K) 0 | |
[256K, 512K) 0 | |
[512K, 1M) 0 | |
[1M, 2M) 1 |@ |
[2M, 4M) 16 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4M, 8M) 0 | |
[8M, 16M) 1 |@ |
@sectors[aarch64-linux-g]:
(..., 0) 2263 |@@@@@@@@@@@@@@@@@@@@@@@ |
[0] 4960 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1] 0 | |
[2, 4) 0 | |
[4, 8) 0 | |
[8, 16) 761 |@@@@@@@ |
[16, 32) 631 |@@@@@@ |
[32, 64) 499 |@@@@@ |
[64, 128) 440 |@@@@ |
[128, 256) 472 |@@@@ |
[256, 512) 242 |@@ |
[512, 1K) 113 |@ |
[1K, 2K) 160 |@ |
[2K, 4K) 191 |@@ |
[4K, 8K) 170 |@ |
[8K, 16K) 91 | |
[16K, 32K) 66 | |
[32K, 64K) 40 | |
[64K, 128K) 79 | |
[128K, 256K) 107 |@ |
[256K, 512K) 134 |@ |
[512K, 1M) 150 |@ |
[1M, 2M) 163 |@ |
[2M, 4M) 77 | |
[4M, 8M) 25 | |
[8M, 16M) 25 | |
[16M, 32M) 128 |@ |
seeksize.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing block I/O requested seeks... Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_issue
{
if (@last[args->dev]) {
// calculate requested seek distance
$last = @last[args->dev];
$dist = (args->sector - $last) > 0 ?
args->sector - $last : $last - args->sector;
// store details
@sectors[args->comm] = hist($dist);
}
// save last requested position of disk head
@last[args->dev] = args->sector + args->nr_sector;
}
END {
clear(@last);
}
seeksize works by looking at the requested sector offset for each device I/O, and comparing it to a recorded previous location. If the script is changed to use the block_rq_completion tracepoint, it will show the actual seeks encountered by the disk. But instead it uses the block_rq_issue tracepoint to answer a different question: how random is the workload the application is requesting? This randomness may change after the I/O is processed by the Linux I/O scheduler, and by the on-disk scheduler.
9.3.6 biopattern
biopattern is a bpftrace tool to identify the pattern of I/O: random or sequential.
# ./biopattern.bt
Attaching 4 probes...
TIME %RND %SEQ COUNT KBYTES
14:02:14 0 0 0 0
14:02:15 50 50 32 476
14:02:16 76 23 156 2356
14:02:17 81 18 424 5052
14:02:18 77 22 529 7048
14:02:19 80 19 345 4924
14:02:20 98 1 173 3772
14:02:21 94 5 271 8664
14:02:22 99 0 863 8128
14:02:23 89 10 972 17180
14:02:24 92 7 1157 18812
biopattern.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("%-8s %5s %5s %8s %10s\n", "TIME", "%RND", "%SEQ", "COUNT", "KBYTES");
}
tracepoint:block:block_rq_complete
{
if (@lastsector[args->dev] == args->sector) {
@sequential++;
} else {
@random++;
}
@bytes = @bytes + args->nr_sector * 512;
@lastsector[args->dev] = args->sector + args->nr_sector;
}
interval:s:1
{
$count = @random + @sequential;
$div = $count;
if ($div == 0) {
$div = 1;
}
time("%H:%M:%S ");
printf("%5d %5d %8d %10d\n", @random * 100 / $div,
@sequential * 100 / $div, $count, @bytes / 1024);
clear(@random);
clear(@sequential);
clear(@bytes);
}
END
{
clear(@lastsector);
clear(@random);
clear(@sequential);
clear(@bytes);
}
This works by instrumenting block I/O completion, and remembering the last sector (disk address) used for each device, so that it can be compared with the following I/O to see if it carried on from the previous address (sequential) or did not (random)
9.3.7 biostacks
biostacks is a bpftrace tool that traces full I/O latency (from OS enqueue to device completion) with the I/O initialization stack trace.
# ./biostacks.bt
Attaching 5 probes...
cannot attach kprobe, probe entry may not exist
Warning: could not attach probe kprobe:blk_start_request, skipping.
Tracing block I/O with init stacks. Hit Ctrl-C to end.
^C
@usecs[
blk_account_io_start+0
blk_mq_bio_list_merge+236
__blk_mq_sched_bio_merge+256
blk_mq_make_request+220
generic_make_request+180
submit_bio+76
ext4_mpage_readpages+408
ext4_readpages+72
read_pages+116
__do_page_cache_readahead+420
ondemand_readahead+308
page_cache_async_readahead+248
generic_file_read_iter+1816
ext4_file_read_iter+88
new_sync_read+268
__vfs_read+60
vfs_read+168
ksys_read+112
__arm64_sys_read+36
el0_svc_common.constprop.3+172
do_el0_svc+44
el0_svc+24
el0_sync_handler+300
el0_sync+344
]:
[128K, 256K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
@usecs[
blk_account_io_start+0
generic_make_request+180
submit_bio+76
ext4_mpage_readpages+408
ext4_readpages+72
read_pages+116
__do_page_cache_readahead+420
filemap_fault+1756
ext4_filemap_fault+60
__do_fault+92
__handle_mm_fault+1148
handle_mm_fault+280
do_page_fault+332
do_translation_fault+120
do_mem_abort+72
el1_abort+44
el1_sync_handler+236
el1_sync+124
__arch_clear_user+12
search_binary_handler+144
__do_execve_file.isra.49+1300
__arm64_sys_execve+76
el0_svc_common.constprop.3+172
do_el0_svc+44
el0_svc+24
el0_sync_handler+300
el0_sync+344
]:
[128K, 256K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[256K, 512K) 0 | |
[512K, 1M) 0 | |
[1M, 2M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
biostacks.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing block I/O with init stacks. Hit Ctrl-C to end.\n");
}
kprobe:blk_account_io_start
{
@reqstack[arg0] = kstack;
@reqts[arg0] = nsecs;
}
kprobe:blk_start_request,
kprobe:blk_mq_start_request
/@reqts[arg0]/
{
@usecs[@reqstack[arg0]] = hist(nsecs - @reqts[arg0]);
delete(@reqstack[arg0]);
delete(@reqts[arg0]);
}
END
{
clear(@reqstack);
clear(@reqts);
}
This works by saving the kernel stack and a timestamp when the I/O was initiated, and retrieving that saved stack and timestamp when the I/O completed. These are saved in a map keyed by the struct request pointer, which is arg0 to the traced kernel functions. The kernel stack trace is recorded using the kstack builtin. You can change this to ustack to record the user-level stack trace, or add them both.
9.3.8 bioerr
bioerr traces block I/O errors and prints details.
# ./bioerr.bt
Attaching 2 probes...
Tracing block I/O errors. Hit Ctrl-C to end.
01:44:41 device: 8,0, sector: 969222536, bytes: 4096, flags: W, error: -5
01:44:41 device: 8,0, sector: 969222560, bytes: 90112, flags: W, error: -5
01:44:41 device: 8,0, sector: 969222736, bytes: 106496, flags: W, error: -5
01:44:41 device: 8,0, sector: 969222544, bytes: 8192, flags: W, error: -5
01:44:41 device: 8,0, sector: 486803736, bytes: 77824, flags: WS, error: -5
01:44:41 device: 8,0, sector: 486803456, bytes: 4096, flags: WS, error: -5
[...]
biostacks, was created to investigate this kind of issue.
We can tweak biostacks to do this, it can also be done as a bpftrace one-liner (in this case, I’ll check that the stack trace is still meaningful by the time we hit this tracepoint; if it was not, I’d need to switch back to a kprobe of blk_account_io_start() to really catch the initialization of this I/O):
# bpftrace -e 't:block:block_rq_issue /args->dev == 8/ { @[kstack]++ }'
# bpftrace -e 'kprobe:blk_account_io_start { @[kstack]++ }'
From the kernel stack, we know the usb drive was removed(usb_disconnect):
# bpftrace -e 'kprobe:blk_account_io_start { @[kstack]++ }'
Attaching 1 probe...
^C
[...]
@[
blk_account_io_start+0
blk_attempt_plug_merge+348
blk_mq_make_request+872
generic_make_request+180
submit_bio+76
submit_bh_wbc+404
__block_write_full_page+612
block_write_full_page+276
blkdev_writepage+36
__writepage+40
write_cache_pages+476
generic_writepages+104
blkdev_writepages+24
do_writepages+104
__filemap_fdatawrite_range+236
filemap_flush+36
__sync_blockdev+64
sync_filesystem+112
fsync_bdev+44
invalidate_partition+44
del_gendisk+208
sd_remove+100
device_release_driver_internal+256
device_release_driver+32
bus_remove_device+304
device_del+356
__scsi_remove_device+272
scsi_forget_host+128
scsi_remove_host+124
usb_stor_disconnect+84
usb_unbind_interface+120
device_release_driver_internal+256
device_release_driver+32
bus_remove_device+304
device_del+356
usb_disable_device+156
usb_disconnect+208
hub_event+1928
process_one_work+500
worker_thread+76
kthread+360
ret_from_fork+16
]: 2
bioerr.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing block I/O errors. Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_complete
/args->error != 0/
{
time("%H:%M:%S ");
printf("device: %d,%d, sector: %d, bytes: %d, flags: %s, error: %d\n",
args->dev >> 20, args->dev & ((1 << 20) - 1), args->sector,
args->nr_sector * 512, args->rwbs, args->error);
}
The logic for mapping the device identifier (args->dev) to the major and minor numbers comes from the format file for this tracepoint:
# cat /sys/kernel/debug/tracing/events/block/block_rq_complete/format
name: block_rq_complete
[...]
print fmt: "%d,%d %s (%s) %llu + %u [%d]", ((unsigned int) ((REC->dev) >> 20)), ((unsigned int) ((REC->dev) & ((1U << 20) - 1))), REC->rwbs, __get_str(cmd), (unsigned long long)REC->sector, REC->nr_sector, REC->error
perf can be used for similar functionality by filtering on error:
# perf record -e block:block_rq_complete --filter 'error != 0'
# perf script
9.3.9 iosched
iosched traces the time that requests were queued in the I/O scheduler, and groups this by scheduler name.
iosched.bt
#!/usr/bin/bpftrace
#include <linux/blkdev.h>
BEGIN
{
printf("Tracing block I/O schedulers. Hit Ctrl-C to end.\n");
}
kprobe:__elv_add_request
{
@start[arg1] = nsecs;
}
kprobe:blk_start_request,
kprobe:blk_mq_start_request
/@start[arg0]/
{
$r = (struct request *)arg0;
@usecs[$r->q->elevator->type->elevator_name] = hist((nsecs - @start[arg0]) / 1000);
delete(@start[arg0]);
}
END
{
clear(@start);
}
This works by recording a timestamp when requests were added to an I/O scheduler via an elevator function, __elv_add_request(), and then calculating the time queued when the I/O was issued. This focuses tracing I/O to only those that pass via an I/O scheduler, and also focuses on tracing just the queued time. The scheduler ( elevator) name is fetched from the struct request.
Unfortunately, iosched report error while attaching probe:
# ./iosched.bt
Attaching 5 probes...
cannot attach kprobe, probe entry may not exist
Warning: could not attach probe kprobe:blk_start_request, skipping.
cannot attach kprobe, probe entry may not exist
Error attaching probe: 'kprobe:__elv_add_request'
The kernel I am using is 5.7.8, dumping kernel stack with tracepoint reveals what is the correct probe I should be using:
# bpftrace -e 't:block:block_rq_insert { printf("%s", kstack); }'
Attaching 1 probe...
blk_mq_insert_requests+240
blk_mq_insert_requests+240
blk_mq_sched_insert_requests+384
blk_mq_flush_plug_list+352
blk_flush_plug_list+228
blk_finish_plug+64
__ext4_get_inode_loc+692
__ext4_iget+280
ext4_lookup+348
__lookup_slow+168
walk_component+284
path_lookupat.isra.46+124
filename_lookup.part.62+140
user_path_at_empty+88
vfs_statx+152
__do_sys_newfstatat+60
__arm64_sys_newfstatat+40
el0_svc_common.constprop.3+172
do_el0_svc+44
el0_svc+24
el0_sync_handler+300
el0_sync+344
Another point need to note is elevator_name in include/linux/elevator.h is changed
from array to pointer:
char elevator_name[ELV_NAME_MAX]; ==> const char *elevator_name;
This is the updated version of iosched.bt:
#!/usr/bin/bpftrace
#include <linux/blkdev.h>
BEGIN
{
printf("Tracing block I/O schedulers. Hit Ctrl-C to end.\n");
}
kprobe:blk_mq_sched_request_inserted
{
@start[arg0] = nsecs;
}
kprobe:blk_start_request,
kprobe:blk_mq_start_request
/@start[arg0]/
{
$r = (struct request *)arg0;
@usecs[str($r->q->elevator->type->elevator_name)] = hist((nsecs - @start[arg0]) / 1000);
delete(@start[arg0]);
}
END
{
clear(@start);
}
# ./iosched.bt
Attaching 5 probes...
cannot attach kprobe, probe entry may not exist
Warning: could not attach probe kprobe:blk_start_request, skipping.
Tracing block I/O schedulers. Hit Ctrl-C to end.
^C
@usecs[mq-deadline]:
[32, 64) 78 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[64, 128) 68 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[128, 256) 24 |@@@@@@@@@@@@@@@@ |
[256, 512) 0 | |
[512, 1K) 7 |@@@@ |
[1K, 2K) 65 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[2K, 4K) 42 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4K, 8K) 34 |@@@@@@@@@@@@@@@@@@@@@@ |
[8K, 16K) 2 |@ |
[16K, 32K) 1 | |
9.3.10 scsilatency
scsilatency is a tool to trace SCSI commands with latency distributions.
# ./scsilatency.bt
Attaching 5 probes...
cannot attach kprobe, probe entry may not exist
Warning: could not attach probe kprobe:scsi_done, skipping.
Tracing scsi latency. Hit Ctrl-C to end.
^C
@usecs[40, READ_10]:
[256, 512) 5 |@@@@@@@ |
[512, 1K) 34 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1K, 2K) 4 |@@@@@@ |
[2K, 4K) 3 |@@@@ |
[4K, 8K) 10 |@@@@@@@@@@@@@@@ |
[8K, 16K) 24 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[16K, 32K) 9 |@@@@@@@@@@@@@ |
[32K, 64K) 2 |@@@ |
@usecs[42, WRITE_10]:
[256, 512) 3 |@ |
[512, 1K) 64 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1K, 2K) 35 |@@@@@@@@@@@@@@@@@@ |
[2K, 4K) 99 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4K, 8K) 12 |@@@@@@ |
scsilatency.bt
#!/usr/bin/bpftrace
#include <scsi/scsi_cmnd.h>
BEGIN
{
printf("Tracing scsi latency. Hit Ctrl-C to end.\n");
// SCSI opcodes from scsi/scsi_proto.h; add more mappings if desired:
@opcode[0x00] = "TEST_UNIT_READY";
@opcode[0x03] = "REQUEST_SENSE";
@opcode[0x08] = "READ_6";
@opcode[0x0a] = "WRITE_6";
@opcode[0x0b] = "SEEK_6";
@opcode[0x12] = "INQUIRY";
@opcode[0x18] = "ERASE";
@opcode[0x28] = "READ_10";
@opcode[0x2a] = "WRITE_10";
@opcode[0x2b] = "SEEK_10";
@opcode[0x35] = "SYNCHRONIZE_CACHE";
}
kprobe:scsi_init_io
{
@start[arg0] = nsecs;
}
kprobe:scsi_done,
kprobe:scsi_mq_done
/@start[arg0]/
{
$cmnd = (struct scsi_cmnd *)arg0;
$opcode = *$cmnd->req.cmd & 0xff;
@usecs[$opcode, @opcode[$opcode]] = hist((nsecs - @start[arg0]) / 1000);
}
END
{
clear(@start); clear(@opcode);
}
9.3.11 scsiresult
scsiresult summarizes SCSI command results: the host and status codes.
# ./scsiresult.bt
Attaching 3 probes...
Tracing scsi command results. Hit Ctrl-C to end.
^C
@[DID_OK, SAM_STAT_GOOD]: 732
scsiresult.bt
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing scsi command results. Hit Ctrl-C to end.\n");
// host byte codes, from include/scsi/scsi.h:
@host[0x00] = "DID_OK";
@host[0x01] = "DID_NO_CONNECT";
@host[0x02] = "DID_BUS_BUSY";
@host[0x03] = "DID_TIME_OUT";
@host[0x04] = "DID_BAD_TARGET";
@host[0x05] = "DID_ABORT";
@host[0x06] = "DID_PARITY";
@host[0x07] = "DID_ERROR";
@host[0x08] = "DID_RESET";
@host[0x09] = "DID_BAD_INTR";
@host[0x0a] = "DID_PASSTHROUGH";
@host[0x0b] = "DID_SOFT_ERROR";
@host[0x0c] = "DID_IMM_RETRY";
@host[0x0d] = "DID_REQUEUE";
@host[0x0e] = "DID_TRANSPORT_DISRUPTED";
@host[0x0f] = "DID_TRANSPORT_FAILFAST";
@host[0x10] = "DID_TARGET_FAILURE";
@host[0x11] = "DID_NEXUS_FAILURE";
@host[0x12] = "DID_ALLOC_FAILURE";
@host[0x13] = "DID_MEDIUM_ERROR";
// status byte codes, from include/scsi/scsi_proto.h:
@status[0x00] = "SAM_STAT_GOOD";
@status[0x02] = "SAM_STAT_CHECK_CONDITION";
@status[0x04] = "SAM_STAT_CONDITION_MET";
@status[0x08] = "SAM_STAT_BUSY";
@status[0x10] = "SAM_STAT_INTERMEDIATE";
@status[0x14] = "SAM_STAT_INTERMEDIATE_CONDITION_MET";
@status[0x18] = "SAM_STAT_RESERVATION_CONFLICT";
@status[0x22] = "SAM_STAT_COMMAND_TERMINATED";
@status[0x28] = "SAM_STAT_TASK_SET_FULL";
@status[0x30] = "SAM_STAT_ACA_ACTIVE";
@status[0x40] = "SAM_STAT_TASK_ABORTED";
}
tracepoint:scsi:scsi_dispatch_cmd_done
{
@[@host[(args->result >> 16) & 0xff], @status[args->result & 0xff]] = count();
}
END
{
clear(@status);
clear(@host);
}
The result also has driver and message bytes, not shown by this tool. It is of the format:
driver_byte << 24 | host_byte << 16 | msg_byte << 8 | status_byte
This tool can be enhanced to add these bytes and other detail(shown below) to the map as additional keys:
# bpftrace -lv t:scsi:scsi_dispatch_cmd_done
tracepoint:scsi:scsi_dispatch_cmd_done
unsigned int host_no;
unsigned int channel;
unsigned int id;
unsigned int lun;
int result;
unsigned int opcode;
unsigned int cmd_len;
unsigned int data_sglen;
unsigned int prot_sglen;
unsigned char prot_op;
__data_loc unsigned char[] cmnd;
9.4 BPF ONE-LINERS
Count block I/O tracepoints:
funccount t:block:*
bpftrace -e 'tracepoint:block:* { @[probe] = count(); }'
Examples:
# funccount-bpfcc t:block:*
Tracing 18 functions for "b't:block:*'"... Hit Ctrl-C to end.
^C
FUNC COUNT
block:block_split 4
block:block_bio_frontmerge 5
block:block_plug 57
block:block_unplug 57
block:block_rq_complete 63
block:block_rq_insert 63
block:block_rq_issue 63
block:block_getrq 64
block:block_bio_backmerge 69
block:block_bio_queue 134
block:block_bio_remap 134
block:block_dirty_buffer 596
block:block_touch_buffer 1354
Detaching...
# bpftrace -e 'tracepoint:block:* { @[probe] = count(); }'
Attaching 18 probes...
^C
@[tracepoint:block:block_rq_insert]: 2
@[tracepoint:block:block_bio_backmerge]: 6
@[tracepoint:block:block_plug]: 8
@[tracepoint:block:block_unplug]: 8
@[tracepoint:block:block_rq_issue]: 9
@[tracepoint:block:block_getrq]: 9
@[tracepoint:block:block_rq_complete]: 9
@[tracepoint:block:block_bio_queue]: 15
@[tracepoint:block:block_bio_remap]: 15
@[tracepoint:block:block_dirty_buffer]: 1315
@[tracepoint:block:block_touch_buffer]: 1663
Summarize block I/O size as a histogram:
argdist -H 't:block:block_rq_issue():u32:args->bytes'
bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
Examples:
# argdist-bpfcc -H 't:block:block_rq_issue():u32:args->bytes'
[04:06:26]
args->bytes : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 0 | |
128 -> 255 : 0 | |
256 -> 511 : 0 | |
512 -> 1023 : 0 | |
1024 -> 2047 : 0 | |
2048 -> 4095 : 0 | |
4096 -> 8191 : 1 |****************************************|
8192 -> 16383 : 0 | |
16384 -> 32767 : 1 |****************************************|
# bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
Attaching 1 probe...
^C
@bytes:
[4K, 8K) 26 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8K, 16K) 19 |@@@@@@@@@@@@@@@@@@@@@ |
[16K, 32K) 29 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32K, 64K) 22 |@@@@@@@@@@@@@@@@@@@@@@@@ |
[64K, 128K) 47 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
Count block I/O request user stack traces:
stackcount -U t:block:block_rq_issue
bpftrace -e 't:block:block_rq_issue { @[ustack] = count(); }'
Count block I/O type flags:
argdist -C 't:block:block_rq_issue():char*:args->rwbs'
bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = count(); }'
Examples:
# argdist-bpfcc -C 't:block:block_rq_issue():char*:args->rwbs'
[04:12:06]
t:block:block_rq_issue():char*:args->rwbs
COUNT EVENT
[04:12:07]
t:block:block_rq_issue():char*:args->rwbs
COUNT EVENT
1 args->rwbs = b'WS'
1 args->rwbs = b'W'
1 args->rwbs = b'W'
2 args->rwbs = b'WS'
4 args->rwbs = b'W'
5 args->rwbs = b'W'
7 args->rwbs = b'W'
9 args->rwbs = b'W'
9 args->rwbs = b'W'
17 args->rwbs = b'W'
[...]
# bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = count(); }'
Attaching 1 probe...
^C
@[RA]: 7
@[WM]: 26
@[WS]: 33
@[W]: 708
Total bytes by I/O type:
bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = sum(args->bytes); }'
Examples:
# bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = sum(args->bytes); }'
Attaching 1 probe...
^C
@[FF]: 0
@[WFS]: 4096
@[WS]: 241664
@[W]: 311296
@[W]: 1855488
Trace block I/O errors with device and I/O type:
trace 't:block:block_rq_complete (args->error) "dev %d type %s error %d", args->dev, args->rwbs, args->error'
bpftrace -e 't:block:block_rq_complete /args->error/ { printf("dev %d type %s error %d\n", args->dev, args->rwbs, args->error); }'
Summarize block I/O plug time as a histogram:
bpftrace -e 'k:blk_start_plug { @ts[arg0] = nsecs; } k:blk_flush_plug_list /@ts[arg0]/ { @plug_ns = hist(nsecs - @ts[arg0]); delete(@ts[arg0]); }'
Examples:
# bpftrace -e 'k:blk_start_plug { @ts[arg0] = nsecs; } k:blk_flush_plug_list /@ts[arg0]/ { @plug_ns = hist(nsecs - @ts[arg0]); delete(@ts[arg0]); }'
Attaching 2 probes...
^C
@plug_ns:
[16K, 32K) 954 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32K, 64K) 30 |@ |
[64K, 128K) 18 | |
[128K, 256K) 12 | |
[256K, 512K) 0 | |
[512K, 1M) 1 | |
[1M, 2M) 4 | |
[2M, 4M) 3 | |
@ts[-140737149814392]: 513122130121463
@ts[-140737130022520]: 513127254965056
Count SCSI opcodes:
argdist -C 't:scsi:scsi_dispatch_cmd_start():u32:args->opcode'
bpftrace -e 't:scsi:scsi_dispatch_cmd_start { @opcode[args->opcode] = count(); }'
Examples:
# argdist-bpfcc -C 't:scsi:scsi_dispatch_cmd_start():u32:args->opcode'
[11:08:37]
t:scsi:scsi_dispatch_cmd_start():u32:args->opcode
COUNT EVENT
113 args->opcode = 40
[11:08:38]
t:scsi:scsi_dispatch_cmd_start():u32:args->opcode
COUNT EVENT
204 args->opcode = 40
[11:08:39]
t:scsi:scsi_dispatch_cmd_start():u32:args->opcode
COUNT EVENT
1 args->opcode = 42
131 args->opcode = 40
[...]
# bpftrace -e 't:scsi:scsi_dispatch_cmd_start { @opcode[args->opcode] = count(); }'
Attaching 1 probe...
^C
@opcode[42]: 8
@opcode[40]: 2116
Count SCSI result codes:
argdist -C 't:scsi:scsi_dispatch_cmd_done():u32:args->result'
bpftrace -e 't:scsi:scsi_dispatch_cmd_done { @result[args->result] = count(); }'
Examples:
# argdist-bpfcc -C 't:scsi:scsi_dispatch_cmd_done():u32:args->result'
[11:10:36]
t:scsi:scsi_dispatch_cmd_done():u32:args->result
COUNT EVENT
460 args->result = 0
[11:10:37]
t:scsi:scsi_dispatch_cmd_done():u32:args->result
COUNT EVENT
441 args->result = 0
[11:10:38]
t:scsi:scsi_dispatch_cmd_done():u32:args->result
COUNT EVENT
412 args->result = 0
[11:10:39]
t:scsi:scsi_dispatch_cmd_done():u32:args->result
COUNT EVENT
466 args->result = 0
# bpftrace -e 't:scsi:scsi_dispatch_cmd_done { @result[args->result] = count(); }'
Attaching 1 probe...
^C
@result[0]: 7989
Show CPU distribution of blk_mq requests:
bpftrace -e 'k:blk_mq_start_request { @swqueues = lhist(cpu, 0, 100, 1); }'
Examples:
# bpftrace -e 'k:blk_mq_start_request { @swqueues = lhist(cpu, 0, 100, 1); }'
Attaching 1 probe...
^C
@swqueues:
[0, 1) 59 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1, 2) 6 |@@ |
[2, 3) 37 |@@@@@@@@@@@@@@@@@ |
[3, 4) 92 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4, 5) 107 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[5, 6) 11 |@@@@@ |
[6, 7) 0 | |
[7, 8) 70 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
Count scsi driver functions:
bpftrace -e 'kprobe:scsi* { @[func] = count(); }'
Example:
# bpftrace -e 'kprobe:scsi* { @[func] = count(); }'
Attaching 242 probes...
^C
@[scsi_mq_put_budget]: 7
@[scsi_uninit_cmd]: 2933
@[scsi_softirq_done]: 3094
@[scsi_req_init]: 3306
@[scsi_queue_rq]: 3374
@[scsi_mq_done]: 3545
@[scsi_log_send]: 3608
@[scsi_log_completion]: 3630
@[scsi_io_completion]: 3739
@[scsi_init_io]: 3792
@[scsi_init_command]: 3817
@[scsi_handle_queue_ramp_up]: 3942
@[scsi_free_sgtables]: 4000
@[scsi_finish_command]: 4047
@[scsi_end_request]: 4115
@[scsi_device_unbusy]: 4276
@[scsi_decide_disposition]: 4443
@[scsi_dec_host_busy]: 4451
@[scsi_mq_get_budget]: 7398
9.5 OPTIONAL EXERCISES
- Modify biolatency to print a linear histogram instead, for the range 0 to 100 milliseconds and a step size of one millisecond.
- Modify biolatency to print the linear histogram summary every one second
- Develop a tool to show disk I/O completions by CPU, to check how these interrupts are balanced. It could be displayed as a linear histogram.
- Develop a tool similar to biosnoop to print per-event block I/O, with only the following fields, in CSV format: completion_time,direction,latency_ms. The direction is read or write.
- Save two minutes of (4) and use plotting software to visualize it as a scatter plot, coloring reads red and writes blue.
- Save two minutes of the output of (2) and use plotting software to display it as a latency heat map. (You can also develop some plotting software: e.g., use awk to turn the count column into rows of a HTML table, with the background color scaled to the value.)
- Rewrite biosnoop to use block tracepoints.
- Modify seeksize to show the actual seek distances encountered by the storage devices: measured on completions.
- Write a tool to show disk I/O timeouts. One solution could be to use the block tracepoints and BLK_STS_TIMEOUT (see bioerr).
- (Advanced, unsolved) Develop a tool that shows the lengths of block I/O merging as a histogram.